Introduzione
Azure OpenAI Service è una nuova risorsa in Azure per fornire l’accesso tramite REST API ai potenti modelli di linguaggio di OpenAI, inclusi i modelli della serie GPT-3, Codex e Embeddings. Questi modelli possono essere facilmente adattati al tuo compito specifico, inclusa la generazione di contenuti, la sintesi, la ricerca semantica e la traduzione del linguaggio naturale in codice. Gli utenti possono accedere al servizio tramite le API REST, l’SDK di Python o la nostra interfaccia basata sul web in Azure OpenAI Studio. L’ API principale risponde con del testo (generato dal modello) a partire da un prompt generato in ingresso dall’utente. Analogamente a ChatGPT il testo viene diviso in Token (LLM) che sono o parole intere o pezzi di caratteri e il pricing di ogni chiamata dipende dal numero di token. Una volta creata tale risorsa è necessario deployare un model, vediamo dopo come fare.
In-context learning
I modelli utilizzati da Azure OpenAI utilizzano istruzioni in linguaggio naturale ed esempi forniti durante la chiamata di generazione per identificare il compito richiesto e le competenze necessarie. Quando si utilizza questo approccio, la prima parte del prompt include istruzioni in linguaggio naturale e/o esempi del compito specifico desiderato. Il modello completa quindi il compito prevedendo il pezzo di testo successivo più probabile. Questa tecnica è nota come "in-context" learning. Durante questa fase, in questo modo i modelli non vengono ritrainati, ma forniscono previsioni basate sul contesto incluso nel prompt.
Esistono tre approcci principali per l’apprendimento in contesto: few-shot, one-shot e zero-shot. Questi approcci variano in base alla quantità di dati specifici del compito forniti al modello:
Few-shot
In questo approccio, il modello viene fornito con alcuni esempi o istruzioni specifiche del compito desiderato durante la chiamata di generazione. Gli esempi dimostrano il formato e il contenuto delle risposte attese. Anche se il modello potrebbe non essere stato precedentemente esposto a quel particolare compito o dominio, l'utilizzo di pochi esempi aiuta il modello a comprendere il contesto e a generare completamenti coerenti e pertinenti.
In questo caso scrivo nel prompt numerosi esempi di come voglio la risposta e del suo formato e mi aspetto che il modello generi l’ultima risposta in modo perfettamente coerente con le precedenti che ho fornito io. Il numero di esempi può andare da 2 a 100 in base alla lunghezza massima consentita del prompt.
Convert the questions to a command:
Q: Ask Constance if we need some bread.
A: send-msg `find constance` Do we need some bread?
Q: Send a message to Greg to figure out if things are ready for Wednesday.
A: send-msg `find greg` Is everything ready for Wednesday?
Q: Ask Ilya if we're still having our meeting this evening.
A: send-msg `find ilya` Are we still having a meeting this evening?
Q: Contact the ski store and figure out if I can get my skis fixed before I leave on Thursday.
A: send-msg `find ski store` Would it be possible to get my skis fixed before I leave on Thursday?
Q: Thank Nicolas for lunch.
A: send-msg `find nicolas` Thank you for lunch!
Q: Tell Constance that I won't be home before 19:30 tonight — unmovable meeting.
A: send-msg `find constance` I won't be home before 19:30 tonight. I have a meeting I can't move.
Q: Tell John that I need to book an appointment at 10:30.
A:
One-shot
L’approccio one-shot richiede che il modello venga fornito con un singolo esempio o un'unica istruzione del compito durante la chiamata di generazione. Questo esempio rappresenta un esempio specifico di input e output desiderato. Nonostante l’assenza di un set completo di esempi, il modello cerca di generare un completamento coerente e pertinente basandosi su quel singolo esempio fornito.
Zero-shot
Nell’approccio zero-shot, il modello viene presentato con una descrizione ad alto livello del compito senza esempi specifici. Il modello deve generalizzare e comprendere il compito senza essere stato precedentemente addestrato su esempi o istruzioni specifiche per quel compito. L’obiettivo è che il modello riesca a generare completamenti basati sulla comprensione del contesto e sulla conoscenza generale appresa durante l’addestramento su un’ampia varietà di dati.
Quickstart
Per poter provare Azure OpenAI sono necessari i segenti prerequisiti:
- Account Azure
- L’accesso al servizio di Azure OpenAI che viene concesso solo su richiesta;
- L’ultima versione di .NET Core
- Aver deployato un modello per tale risorsa, per esempio un modello
text-davinci-003oppuregpt35-turbo
Vediamo passo passo come procedere:
Creazione della risorsa
Andiamo nell’Azure Resource Manager e clicchiamo su “Create Resources” e cerchiamo “Azure OpenAI” nel marketplace.
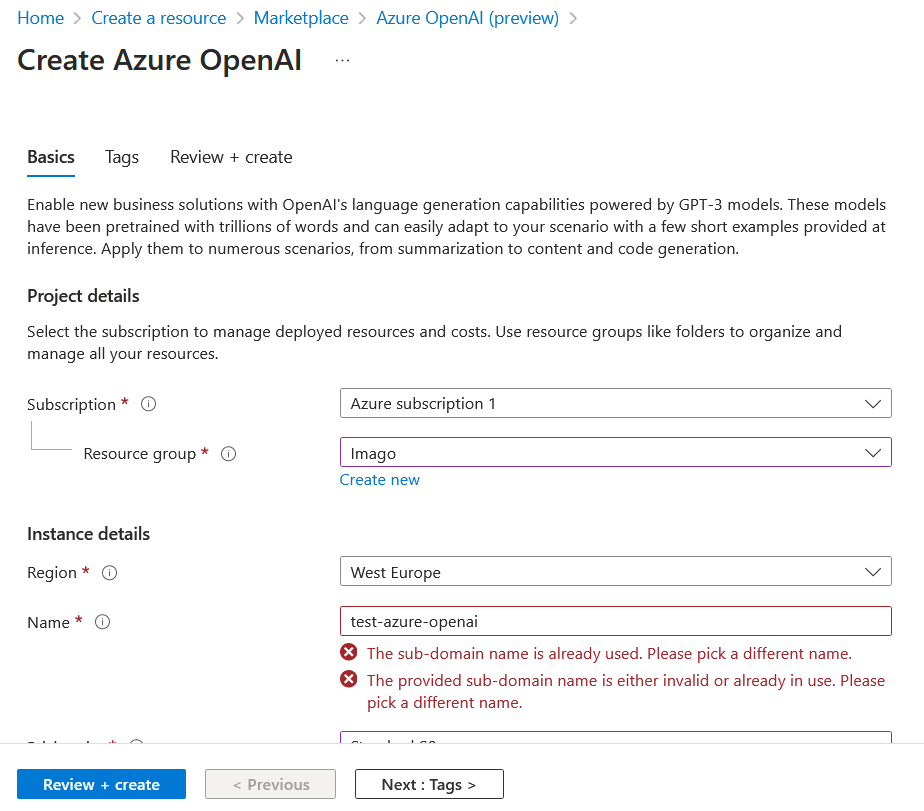
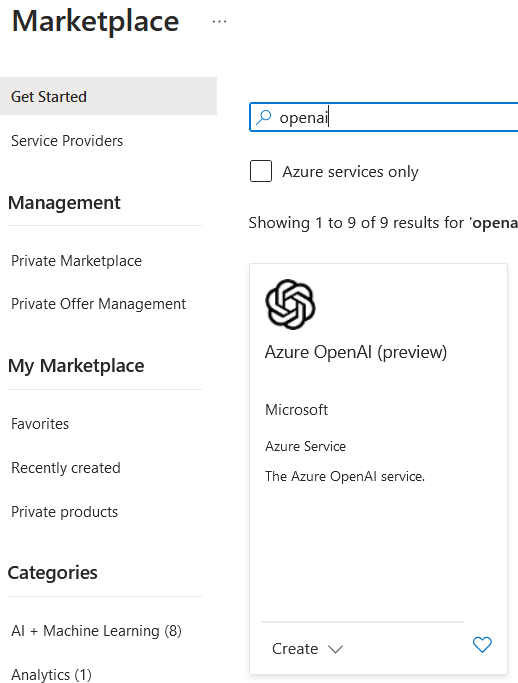 Una volta cliccato compiliamo con i campi richiesti e clicchiamo su “Review+create”.
Una volta cliccato compiliamo con i campi richiesti e clicchiamo su “Review+create”.
 Una volta creata compare la finestra di gestione di tale risorsa.
Una volta creata compare la finestra di gestione di tale risorsa.
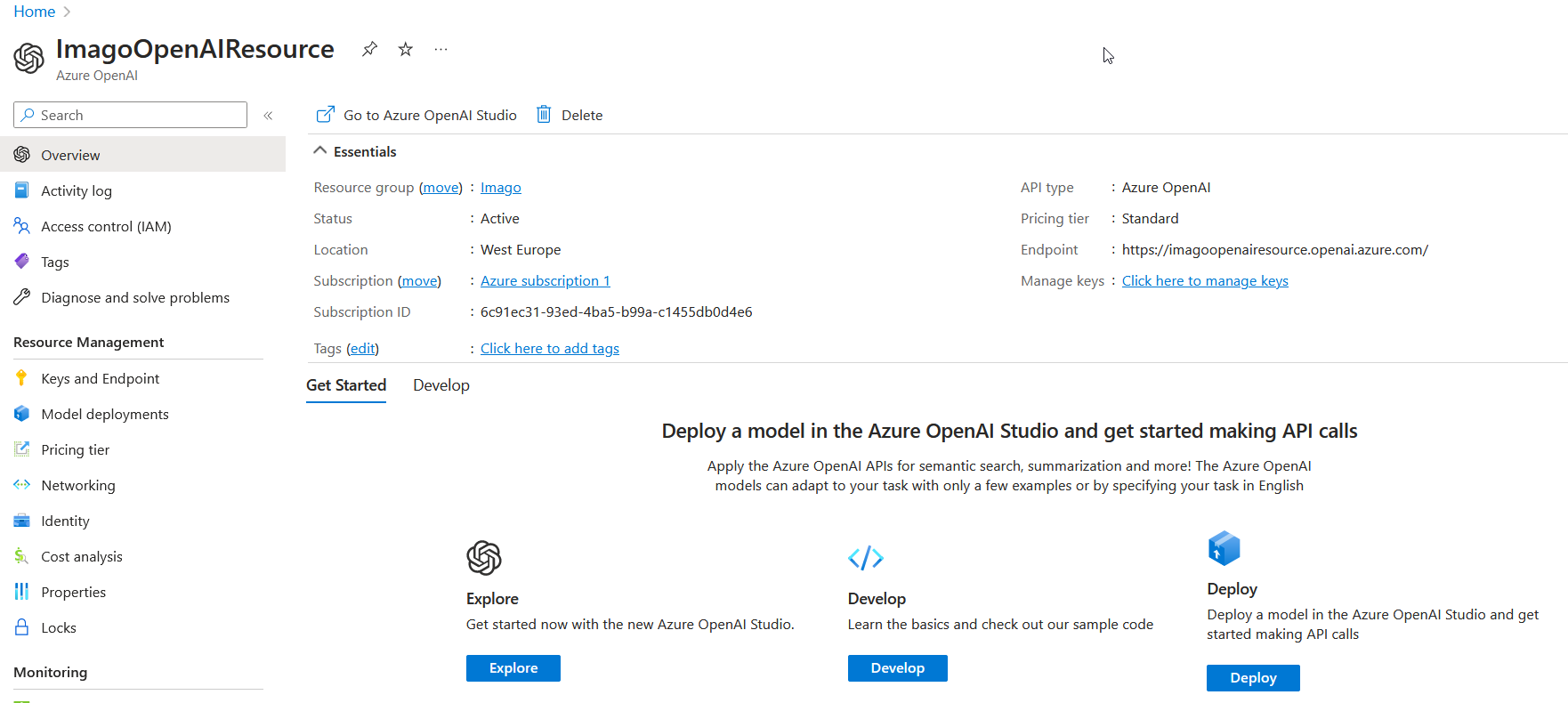
Deploy del modello
Una volta creata è necessario deployare un modello. Per farlo premere sul tasto “Deploy” che apre la nuova interfaccia di Azure per la gestione e il deploy dei modelli per l’IA.
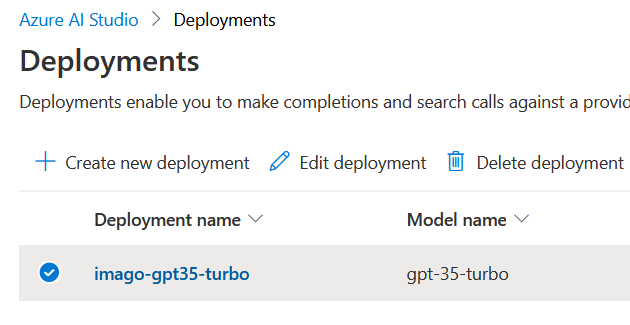
Qui cliccare su “Create new deployment”, selezionare come modello text-davinci-003 oppure gpt-35-turbo, dargli un nome e procedere.
Tip
Segnarsi il nome custom che si è dato al modello in quanto servirà dopo nel codice.
 Per esempio in questo caso ho un modello
Per esempio in questo caso ho un modello gpt35 chiamato imago-gpt35-turbo.
Console application
Per verificare il corretto funzionamento del tutto posso creare una console application importando come pacchetto nuget Azure.AI.OpenAI (checkare il flag prerelease).
Per poter funzionare ho bisogno di 3 cose:
- Endpoint: l’url da chiamare
- Api-key: la chiave per l’autenticazione
- Nome modello: il nome del modello che ho dato in precedenza (nell’esempio di prima è
imago-gpt35-turbo). L’endpoint e l’api-key si possono trovare nella sezioneKeys and Endpointdella risorsa (come api-key sceglierne una delle due, non cambia nulla).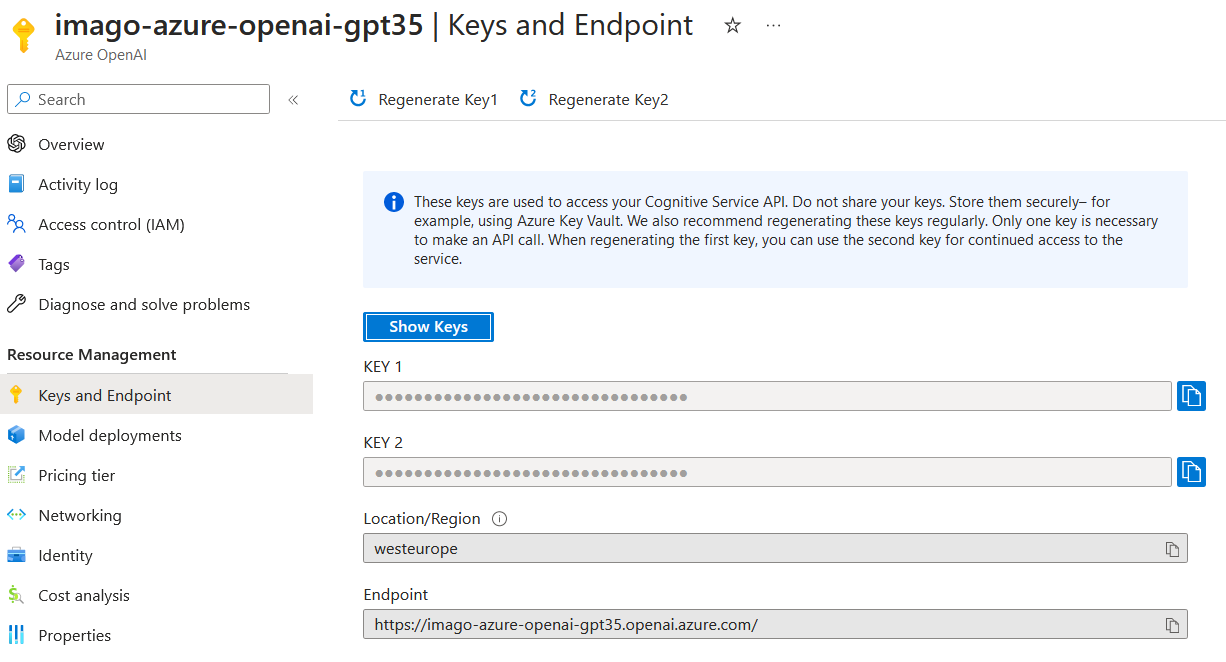 Una volta ottenuti questi valori scriviamo il seguente codice:
Una volta ottenuti questi valori scriviamo il seguente codice:
const string endpoint = "ENDPOINT";
const string key = "API_KEY";
const string engine = "NOME_MODELLO";
OpenAIClient client = new(new Uri(endpoint), new AzureKeyCredential(key));
var chatCompletionsOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatMessage(ChatRole.System, "You are a helpful assistant."),
new ChatMessage(ChatRole.User, "Does Azure OpenAI support customer managed keys?"),
new ChatMessage(ChatRole.Assistant, "Yes, customer managed keys are supported by Azure OpenAI."),
new ChatMessage(ChatRole.User, "Do other Azure Cognitive Services support this too?"),
},
MaxTokens = 100
};
Response<StreamingChatCompletions> response = await client.GetChatCompletionsStreamingAsync(deploymentOrModelName: engine, chatCompletionsOptions);
using var streamingChatCompletions = response.Value;
await foreach (var choice in streamingChatCompletions.GetChoicesStreaming())
await foreach (var message in choice.GetMessageStreaming())
Console.Write(message.Content);
Console.WriteLine(); Se tutto va bene avremo la nostra console application funzionante!