Questa nota prende a piene mani dal corso Getting Started: Solution Architecture.
Introduzione
Partiamo da due definizioni:
Martin Fowler
“Architecture is the shared understanding that the expert developers have of the system design“
o anche
Quote
“Architecture is about the important stuff“
L’obeittivo è identificare le cose importanti per il business di quello che stiamo costruendo e progettare quindi un sistema adatto a rispondere a tali esigenze. Fare delle scelte di design errate all’inizio può portare a problematiche molto costose da risolvere nel lungo periodo, è per quello fondamentale spendere del tempo nel design dell’applicazione che vogliamo creare, ponendo sempre l’attenzione alle richieste del business. E' fondamentale partire con lo studio e la comprensione del problema che dovrò andare a risolvere e le caratteristiche degli utenti che andranno ad utilizzare il software. E’ inoltre fondamentale tenere a mente che il sistema sicuramente cambierà e si evolverà, quindi bisogna già pensarlo nell’ottica per cui la sua modifica non sia difficile o costosa.
System Thinking
Il System Thinking nell’ambito della design architecture software è un approccio che consiste nel considerare il sistema software nel suo insieme, piuttosto che focalizzarsi solo sui singoli componenti. Significa comprendere le relazioni, le interdipendenze e i flussi tra le diverse parti del sistema, tenendo conto del contesto operativo, degli utenti, delle evoluzioni future e delle conseguenze delle scelte progettuali. In pratica, applicare il System Thinking significa:
- Progettare con una visione olistica, anticipando come un cambiamento in una parte del sistema può influenzare le altre.
- Valutare scalabilità, manutenibilità, resilienza e flessibilità come qualità emergenti dell’intero sistema, non solo dei moduli isolati.
- Tenere conto di fattori esterni (es. organizzazione aziendale, processi, infrastruttura) che influenzano o sono influenzati dal software. È particolarmente utile in sistemi complessi o distribuiti, dove l’interazione tra i componenti ha un impatto maggiore delle singole funzionalità.
Modularity, Coupling, Cohesion
1. Modularity
La modularità si riferisce alla suddivisione di un sistema in parti indipendenti chiamate “moduli”. Ogni modulo è una componente autonoma che realizza una funzionalità specifica. La modularità ha diversi vantaggi, tra cui:
- Manutenibilità: è più facile correggere i bug o aggiungere nuove funzionalità senza influire su tutto il sistema.
- Riutilizzabilità: i moduli possono essere riutilizzati in altri sistemi o parti del sistema.
- Semplicità: i moduli sono più facili da comprendere e testare, riducendo la complessità complessiva del sistema.
2. Coupling (Accoppiamento)
Il coupling (o “accoppiamento”) descrive il grado di dipendenza tra i moduli di un sistema. Un basso accoppiamento significa che i moduli sono indipendenti l’uno dall’altro, mentre un accoppiamento alto implica che i moduli sono strettamente legati e dipendono fortemente l’uno dall’altro. Esistono vari tipi di accoppiamento, tra cui:
- Accoppiamento debole (low coupling): i moduli sono indipendenti, e le modifiche a uno non influiscono sugli altri. Questo è un obiettivo importante nella progettazione di software, poiché aumenta la flessibilità e la manutenibilità.
- Accoppiamento forte (high coupling): i moduli dipendono fortemente l’uno dall’altro. Cambiare un modulo potrebbe obbligare a cambiare altri moduli, rendendo il sistema difficile da modificare o estendere.
Un buon design mira a ridurre l’accoppiamento tra moduli per ottenere un sistema più robusto e facilmente estendibile.
I vari tipi di coupling (accoppiamento) descrivono il grado di dipendenza tra i moduli di un sistema software. In un sistema ben progettato, l’obiettivo è ridurre l’accoppiamento per aumentare la flessibilità e la manutenibilità del codice. Ecco una descrizione dei principali tipi di coupling:
Esempi:
- Content Coupling: i moduli condividono lo storage dei dati, esempio db.
- Control Coupling: un modulo controlla il flusso di un altro modulo.
- Functional Coupling: uno dipende dalle funzioni di un altro modulo.
- Sequential Coupling: i moduli sono legati da un ordine di esecuzione.
- Temporal Coupling: i moduli devono essere eseguiti insieme o in sequenze temporali.
L’accoppiamento non è necessariamente un male, dipende da quanto il team con cui lavoro ha controllo sui vari servizi: se il mio team è responsabile di tutto quello che riguarda 3 servizi accoppiati, esempio, può andare anche bene. Il problema si ha quando c’è accoppiamento su servizi su cui non si ha il controllo, come servizi gestiti da altri team o ancora peggio da terze parti.
3. Cohesion
La coesione misura quanto un modulo è focalizzato su una singola responsabilità. Un modulo ad alta coesione contiene funzionalità correlate che lavorano insieme per realizzare un obiettivo comune. La coesione alta è un indicatore di un buon design, in quanto facilita la comprensione, il test e la manutenzione del modulo.
- Alta coesione: significa che tutte le funzioni di un modulo sono strettamente correlate e svolgono compiti simili o complementari. Un modulo con alta coesione è generalmente più facile da comprendere, testare e manutenere.
- Bassa coesione: significa che un modulo svolge compiti diversi e non correlati. Questo può rendere il modulo più complesso e difficile da gestire.
Un buon design cerca di massimizzare la coesione all’interno di ogni modulo, riducendo al minimo la responsabilità del modulo e assicurando che le sue funzioni siano tutte focalizzate su un unico obiettivo.
Step 1 - Domande al businness
Esempio di domande che un software architect dovrebbe fare alle persone ad alto livello nel business (non tecniche quindi):
- Quale è lo scopo principale di questo nuovo sistema?
- Descrivi in modo approfondito lo use case dell’app
- Quanto è critico questo componente? Cosa deve succedere se non funziona?
- Che impatto ha nel business se il componente rimane down per 1h, 6h o 24h?
- Come questo componente si relaziona con gli altri componenti del business?
- Quale è il carico che prevedete? 10 req/s? 10000 req/s ? Potrebbe cambiare in futuro?
- Ci sono delle integrazioni con altri sistemi esterni necessari?
Step 2 - Functional vs Non-Functional Requirements
I Functional Requirements descrivono cosa il sistema deve fare, ovvero le funzionalità specifiche richieste come per esempio
- Autenticazione utente
- Gestione degli ordini
- Ricerca di prodotti
- Invio di notifiche I Non-Functional Requirements invece descrivono come il sistema deve comportarsi, ovvero requisiti qualitativi e di prestazione come per esempio
- Performance: tempi di risposta rapidi
- Scalability: capacità di gestire carichi crescenti: ho un traffico sempre fisso o oscillante con picchi alti? In futuro ci sono possibilità che il traffico aumenti?
- Security: Il sistema deve rispondere agli utenti legittimi anche mentre subisce un attacco? Quali parti del sistema devono essere sicuri al 100%?
- Availability e reliability: per quanto tempo il sistema deve funzionare consecutivamente senza errori? Quanto tempo ci impiega a ritornare up dopo un down? Quale è il MTBF (Minimum Time Between Failure) accettabile?
- Evolvability e Extensability: l’unica caratteristica che hanno sicuramente tutti i software è che questi saranno destinati a cambiare. Evolvability deve sempre essere considerata come top priorità.
- Maintenability e Flexibility: facilità di aggiornamento e modifica. Quanto spesso mi aspetto che cambi?
- Usability: interfaccia intuitiva, facilità d’uso
- Interoperability: con che sistemi diversi si deve integrare?
- Costo Mentre i Functional Requirements, a parità di applicazione da costruire, sono uguali in tutte le aziende del mondo sono i Non-Functional Requirements che invece dipendono dal singolo business che necessita tale applicazione, e sono su questi ultimi che l’architetto deve prestare maggiormente attenzione. Inoltre spesso sono dei trade-off: per esempio non posso ottimizzare sia per sicurezza e affidabilità sia per costo, in quanto se voglio un sistema che sia sempre online qualsiasi cosa accada questo avrà tipicamente un costo maggiore.
Step 3 - Progettare a partire dai Non-Functional Requirements
Una volta raccolti tutti i requirements non bisogna partire subito con la scelta dei servizi o dei linguaggi, quelli sono dettagli implementativi. Bisogna partire dai Non-Functional Requirements fondamentali e strutturare l’applicazione a partire da questi ultimi. Per esempio se il focus deve essere reliability e availability e devo gestire un app per fare degli ordini ad un e-commerce devo avere un load balancer che smista le richieste a n nodi duplicati. In questo modo se un nodo è down le richieste possono andare agli altri. Tali nodi dovranno fare richieste ad un db ma anch’esso può andare down, quindi dovrò strutturare un db clone con sistemi di sincronizzazione e passaggio dall’uno all’altro. Potrei anche progettare un sistema che crea un nuovo nodo qualora un altro sia down per evitare che i nodi rimanenti abbiano un picco di traffico e così via. Se invece il focus sono le performance il mio obiettivo sarà ridurre il numero di hop tra la richiesta dell’utente e il database, quindi magari creare una struttura con una cache (esempio tecnico Redis) cercando di far rispondere alla cache, possibilmente in-memory, a tutte le richieste e successivamente un sistema di sincronizzazione tra cache e database. Questi due esempi per sottolineare come sono i non-functional requirements che permettono di creare l’architetuttura dell’applicazione.
Serverless mindset
Un buon architetto deve avere un mindset serverless first: questo significa cercare di delegare a cloud providers il più possibile per concentrarsi solo su quello che conta. Per esempio se devo avere un db ha senso che pensi io al backup, al fatto che possa andare down, al deploy e così via? Molto meglio delegarlo ad un cloud provider.
Serverless mindset
Lo sviluppatore deve concentrarsi a scrivere codice che da valore, tutto il resto ci pensano i cloud providers.
I servizi serverless offrono automaticamente:
- Scalability: possono aggiustare le loro performance in base alle richieste in modo automatico
- Availability: sono ridondanti e tipicamente sempre disponibili
Conviene sempre iniziare a progettare un’applicazione prima 100% serverless e poi spostarsi solo nei servizi strettamente necessari. Per esempio se devo fare del machine learning devo avere il controllo totale sulla GPU e per questo non è comodo usare un servizio serverless.
API First Design
Questo pattern si riferisce alla definizione di un contratto tra chi produce e chi consuma o tra chi richiede qualcosa e chi risponde. L’idea è non esternare i miei dettagli del dominio all’esterno in modo da poterli sempre modificare quando voglio ma di creare un contratto con il mondo esterno in modo da avere un disaccoppiamento e un asincronia nello sviluppo. Per esempio una volta definito come sarà un evento che verrà inserito in una cosa, il team di chi sviluppa la produzione di tale evento e il team di chi consumerà tale evento saranno indipendenti, asincroni e disaccoppiati. Analogamente una volta definito il contratto di come sarà la richiesta e la risposta ad una API i due team saranno disaccoppiati.
Streaming vs batch processing
Lo streaming processing e il batch processing sono due modalità di elaborazione dei dati che rispondono a esigenze diverse. Mentre il batch processing si concentra sull’analisi di grandi quantità di dati raccolti in blocchi, tipicamente elaborati a intervalli regolari, lo streaming processing permette invece di analizzare e processare i dati non appena vengono generati. Questo rende lo streaming particolarmente utile quando è necessario ottenere risposte in tempo reale, ad esempio per monitorare sistemi o rilevare anomalie immediatamente.
Scaling
Lo scaling è il processo di aumentare la capacità di un sistema per gestire un carico maggiore, migliorando prestazioni e disponibilità.
Load balancer
Il load balancer è un componente che distribuisce automaticamente il traffico tra più server per ottimizzare l’uso delle risorse, garantire l’affidabilità e ridurre i tempi di risposta. Tipologie:
- Round robin: distribuisce le richieste in modo sequenziale tra i server disponibili.
- Least Connection: assegna le richieste al server con il minor numero di connessioni attive.
- Hashing: utilizza un algoritmo di hash (es. IP client o URL) per indirizzare la richiesta sempre allo stesso server, utile per mantenere la sessione.
Vertical vs horizontal scaling
Lo scaling verticale consiste nell’aumentare le risorse di una singola macchina (CPU, RAM), mentre lo scaling orizzontale aggiunge più istanze di server per distribuire il carico. Lo scaling verticale è finito, nel senso che comunque si arriva ad un limite nell’hardware possibile su una macchina, mentre quello orizzontale è più complesso in quanto prevede l’utilizzo di load balancer ma è potenzialmente infinito.
Caching
Quando un’app cresce, cresce anche la necessità di rispondere più in fretta e alleggerire il carico sui sistemi backend. Una delle soluzioni più semplici ed efficaci è l’uso di una cache, ovvero una memoria veloce dove si salvano temporaneamente i dati più richiesti in modo da evitare ogni volta l’accesso al database o a servizi più lenti, migliorando drasticamente la performance.
Quando tutto va bene e il dato richiesto è già in cache, si parla di cache hit: risposta immediata e zero stress per il database. Quando invece il dato non è in cache, si ha un cache miss: bisogna andare a prenderlo alla fonte, con tempi più lunghi. Per mantenere la cache leggera, si applicano strategie di cache eviction, cioè rimozione dei dati più vecchi o meno usati, spesso secondo regole come LRU (Least Recently Used) o scadenze definite (TTL).
Le modalità di integrazione più comuni sono due:
- Read-through cache: l’app chiede i dati direttamente alla cache. Se il dato non c’è, sarà la cache stessa a recuperarlo dal database, salvarlo e restituirlo.
- Write-through cache: quando si scrive un dato, questo viene aggiornato sia nel database sia nella cache, mantenendola sempre allineata.
Tutto questo, però, ha senso solo se funziona davvero. Per capirlo, l’approccio deve essere data-driven: misurare metriche come il cache hit ratio, i tempi di risposta e il carico sul database è fondamentale per valutare se la cache sta davvero migliorando le performance e in che modo può essere ottimizzata.
Observability
La capacità di osservare un sistema in tempo reale è cruciale per assicurarsi che le richieste per cui il sistema è stato progettato vengano soddisfatte correttamente. In particolare, è essenziale sapere se il sistema sta funzionando come previsto:
- Il sistema sta operando come ci si aspetta?
- I tempi di risposta sono sempre sotto il massimo consentito?
- Ci sono outlier o comportamenti anomali che potrebbero indicare un problema?
Un buon sistema di observability fornisce risposte rapide e precise a queste domande, e ti permette di monitorare le prestazioni e il comportamento del sistema in tempo reale. Per garantire un’adeguata osservabilità, è necessario implementare un sistema di tracing, logging e metriche. Questi strumenti devono essere queryabili, in modo da poter estrarre dati utili e diagnostici per comprendere meglio il comportamento del sistema.
- Tracing: Permette di tracciare il flusso delle richieste attraverso i vari componenti del sistema. Aiuta a comprendere la latenza e la sequenza di eventi durante l’elaborazione di una richiesta.
- Logging: I log forniscono dettagli cruciali sugli eventi che si verificano nel sistema. Essi dovrebbero essere organizzati e strutturati in modo che possano essere facilmente analizzati per diagnosticare problemi.
- Metriche: Le metriche monitorano parametri come i tempi di risposta, il throughput, e l’utilizzo delle risorse. Questi dati aiutano a mantenere il sistema in salute e a identificare eventuali colli di bottiglia o altre anomalie.
Ogni decisione nella progettazione di un’architettura dovrebbe essere guidata dai dati. Il sistema deve essere progettato in modo che possa essere osservato e analizzato in ogni sua parte, permettendo agli ingegneri di prendere decisioni informate basate su informazioni concrete.
Fitness Function
Una fitness function è una funzione matematica che assegna un punteggio a una soluzione, sulla base di quanto essa risponde ai requisiti e agli obiettivi prefissati. Nel design di un sistema, la fitness function viene utilizzata per misurare quanto bene una parte dell’architettura soddisfa i requisiti operativi e prestazionali. Le metriche utilizzate nella fitness function potrebbero includere:
- Performance: Ad esempio, il tempo di risposta delle richieste o il throughput del sistema.
- Affidabilità: Misurata attraverso la percentuale di uptime o la resilienza a guasti.
- Scalabilità: La capacità del sistema di adattarsi a carichi più elevati senza compromettere la performance.
- Sicurezza: Livelli di protezione e resistenza ad attacchi esterni.
- Manutenibilità: La facilità con cui il sistema può essere aggiornato, modificato o riparato senza causare downtime significativo. Le fitness function possono essere testate in modo automatico (per esempio un test e2e che verifica che il tempo di risposta sia inferiore a 100ms) o manuale (esempio test in cui il db va down non possono essere facilmente automatizzabili o comunque testabili ad ogni push nella CI/CD, conseguentemente dovranno essere verificati manualmente o automaticamente una tantum).
Systems integration
Sistemi che controllo
Per far comunicare due sistemi distinti che controllo ci sono varie tecniche, dalle più semplici e immediate alle più complesse.
- Shared file: i sistemi scambiano informazioni tramite file condivisi (es. CSV, XML), letti e scritti in modo asincrono. È semplice ma fragile e poco scalabile.
- Shared database: entrambi i sistemi accedono alla stessa base dati per leggere o scrivere informazioni. È diretto ma crea forti dipendenze e problemi di concorrenza.
- RPC: Remote Procedure Call permette a un sistema di invocare direttamente funzioni o servizi esposti da un altro, spesso tramite HTTP o gRPC. È veloce e sincrono, ma aumenta il coupling.
- Message based: i sistemi comunicano in modo asincrono scambiandosi messaggi attraverso una coda (es. Kafka, RabbitMQ, SQS). Favorisce la decoupling, la resilienza e la scalabilità.
- Point-to-point: un messaggio ha un solo destinatario e viene inserito in una coda; è utile per task distribuiti tra consumatori indipendenti.
- Pub/Sub (Publish/Subscribe): un messaggio viene pubblicato su un bus e può essere ricevuto da più sistemi sottoscritti a cui interessa tale messaggio. Esempio SNS
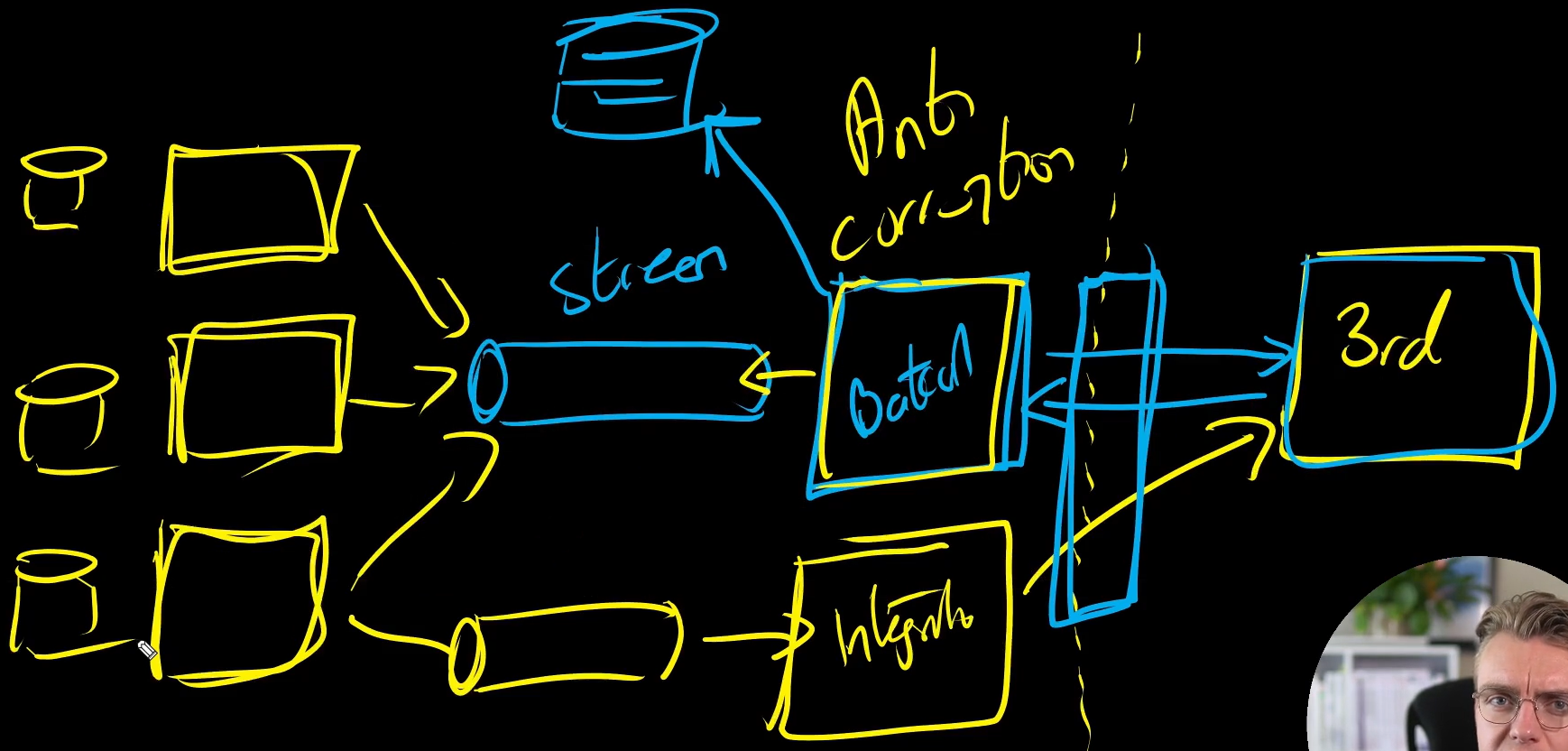
Sistemi di terze parti
Sui sistemi di terze parti con cui devo interagire ho zero controllo: non posso decidere come comunicare, ne come vengono aggiornati o infine quando e come smettono di funzionare.
E’ quindi necessario creare degli oggetti che sono gli unici demandati a comunicare con i sistemi di terze parti e fare in modo che tutti gli altri componenti del mio sistema comunichino sempre e solo con questi oggetti.
In questo modo posso implementare comunicazioni asincrone e disaccoppiamento tra i miei servizi e il comunicatore al mondo esterno e sarà solo lui accoppiato al sistema esterno.
Se questo ultimo cambia le API, per esempio, sarà solo il comunicatore a dover essere cambiato mentre tutti gli altri componenti del sistema non si accorgeranno di nulla.
Per leggere posso implementare un batch process che riceve i dati da un bus popolato dai miei altri servizi. Questo inoltre popolerà una cache in modo da poter rispondere più rapidamente.
Allo stesso modo per le scritture i miei processi scriveranno su un bus con i dati che verranno letti da un integration system che li andrà a scrivere usando le API del servizio esterno.
Documentation
ADR - Architecture Decision Records
ADR - Architecture Decision Records sono dei documenti brevi e strutturati che servono a registrare le decisioni architetturali importanti prese durante lo sviluppo di un software.
L’obiettivo è tenere traccia del “perché” una certa decisione è stata presa, quali alternative erano disponibili e quali motivazioni hanno guidato la scelta. Questo aiuta il team (anche in futuro) a capire il contesto e le ragioni dietro l’architettura del sistema.
Un ADR tipico contiene:
- Titolo della decisione
- Contesto / problema da risolvere
- Decisione presa
- Alternative considerate
- Motivazioni
- Conseguenze
Un ottima lista di template e esempi si trova qui: https://github.com/joelparkerhenderson/architecture-decision-record
Documenting use cases
Oltre agli ADR, è importante anche documentare i casi d’uso, ovvero gli scenari reali di interazione tra gli utenti (o altri sistemi) e il sistema software. Deve essere semplice, specifica e focalizzata sull’utente. I use case descrivono:
- Chi fa cosa (attori coinvolti)
- Come il sistema risponde
- Obiettivi e flussi di lavoro principali
Documentare i casi d’uso aiuta a:
- Comprendere requisiti funzionali
- Validare se l’architettura supporta effettivamente gli scenari d’uso
- Collegare le decisioni architetturali ai bisogni reali degli utenti
Esempio
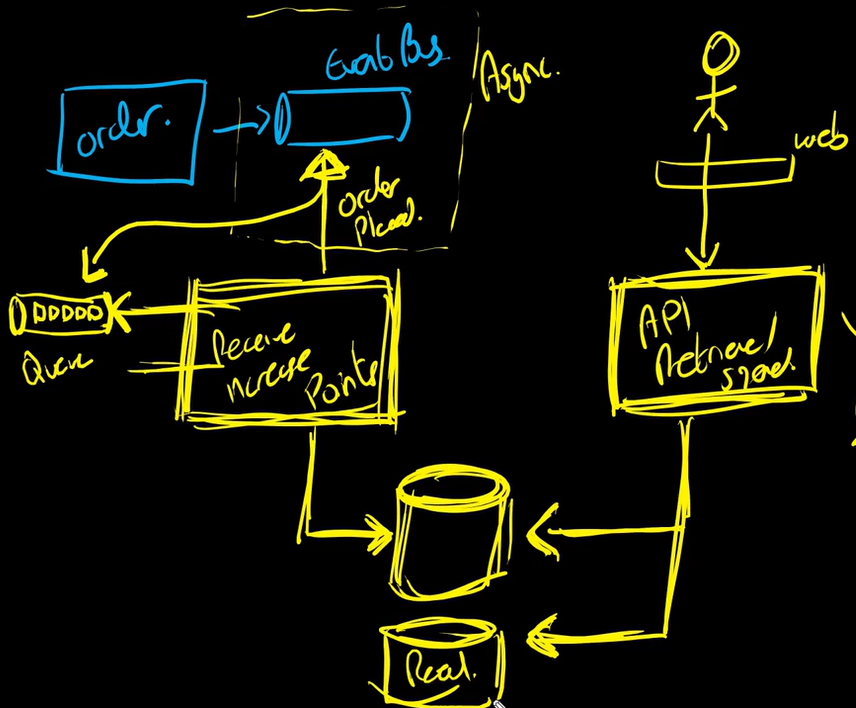 Prendiamo come esempio il dover implementare un sistema di punti fedeltà di e-commerce: quando faccio un ordine aumenteranno i punti e questi ultimi potranno essere usati negli ordini successivi per avere degli sconti.
Posso pensare al sistema come formato da due sistemi diversi: il primo è quello che si occuperà di aggiungere i punti ad un database a seguito di un ordine, il secondo permetterà all’utente di sapere quanti punti ho e di spenderli.
Il primo sistema non deve essere fortemente accoppiato ad un ordine: anche se l’utente non vede immediatamente i punti aggiornati ma passa qualche secondo non cambia nulla.
Posso quindi pensare che l’ordine venga inserito in un bus e reperito da una queue. Il sistema di aggiunta punti prenderà in modo asincrono questi eventi dalla coda e aggiornerà il database.
In questo modo ho implementato basso accoppiamento tra il sistema di gestione degli ordini e quello di aggiunta punti.
Il sistema invece di reperimento punti dovrà essere istantaneo in quanto è a seguito di una richiesta esplicita di un utente, per quello potrebbe essere una classica API CRUD.
Sia il primo che il secondo sistema utilizzeranno un database condiviso in modo da semplificare notevolmente il sistema.
Potrebbe avere senso aggiungere una read replica al db in modo da non avere problemi in caso di down di questo ultimo.
Prendiamo come esempio il dover implementare un sistema di punti fedeltà di e-commerce: quando faccio un ordine aumenteranno i punti e questi ultimi potranno essere usati negli ordini successivi per avere degli sconti.
Posso pensare al sistema come formato da due sistemi diversi: il primo è quello che si occuperà di aggiungere i punti ad un database a seguito di un ordine, il secondo permetterà all’utente di sapere quanti punti ho e di spenderli.
Il primo sistema non deve essere fortemente accoppiato ad un ordine: anche se l’utente non vede immediatamente i punti aggiornati ma passa qualche secondo non cambia nulla.
Posso quindi pensare che l’ordine venga inserito in un bus e reperito da una queue. Il sistema di aggiunta punti prenderà in modo asincrono questi eventi dalla coda e aggiornerà il database.
In questo modo ho implementato basso accoppiamento tra il sistema di gestione degli ordini e quello di aggiunta punti.
Il sistema invece di reperimento punti dovrà essere istantaneo in quanto è a seguito di una richiesta esplicita di un utente, per quello potrebbe essere una classica API CRUD.
Sia il primo che il secondo sistema utilizzeranno un database condiviso in modo da semplificare notevolmente il sistema.
Potrebbe avere senso aggiungere una read replica al db in modo da non avere problemi in caso di down di questo ultimo.