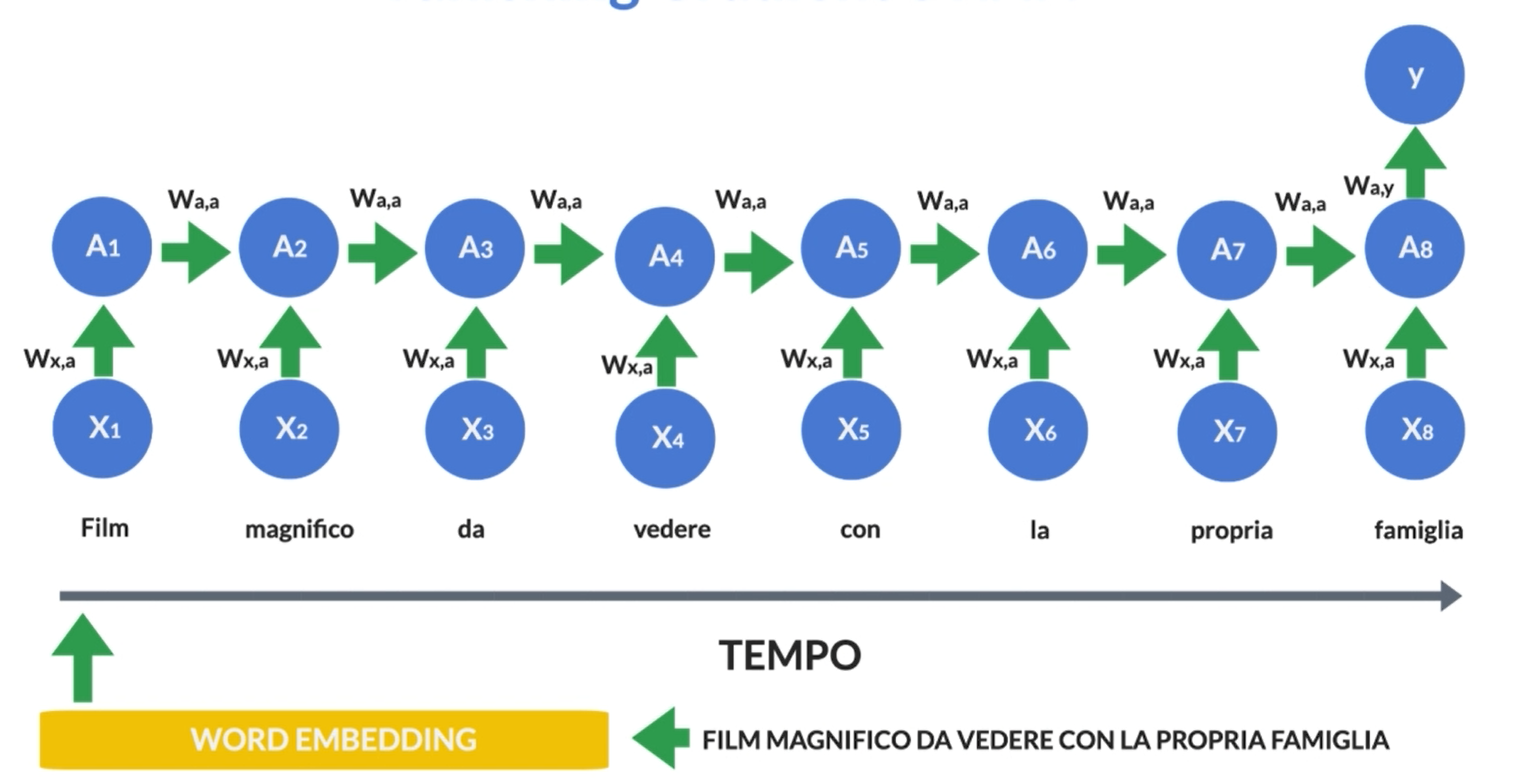
Le reti neurali ricorrenti (RNN) sono un tipo di modello di intelligenza artificiale che, piuttosto che considerare solo i dati in ingresso in un certo momento, come fanno le reti neurali tradizionali, le RNN tengono conto anche delle informazioni precedenti. Immagina di leggere una frase: il significato delle parole successive spesso dipende dalle parole che hai letto prima. Le RNN cercano di catturare questo tipo di relazione sequenziale; infatti possono elaborare un pezzo alla volta e mantenere una "memoria" di ciò che hanno visto in precedenza.
Immagina di leggere una storia. La tua comprensione del significato delle parole successive dipende spesso dalle parole che hai letto prima. Ad esempio, se leggi “Lisa ha deciso di mangiare la pizza perché era affamata”, la tua comprensione di “mangiare” dipende dal fatto che Lisa è affamata. Le RNN cercano di imitare questo processo di “memorizzazione” delle informazioni passate.
Ora, le RNN sono utilizzate in una varietà di applicazioni. Ad esempio, possono essere utilizzate per l’elaborazione del linguaggio naturale (NLP). Questo significa che possono aiutare a comprendere il significato di frasi complesse o addirittura a generare nuovi testi in base a ciò che hanno imparato dalle informazioni precedenti.
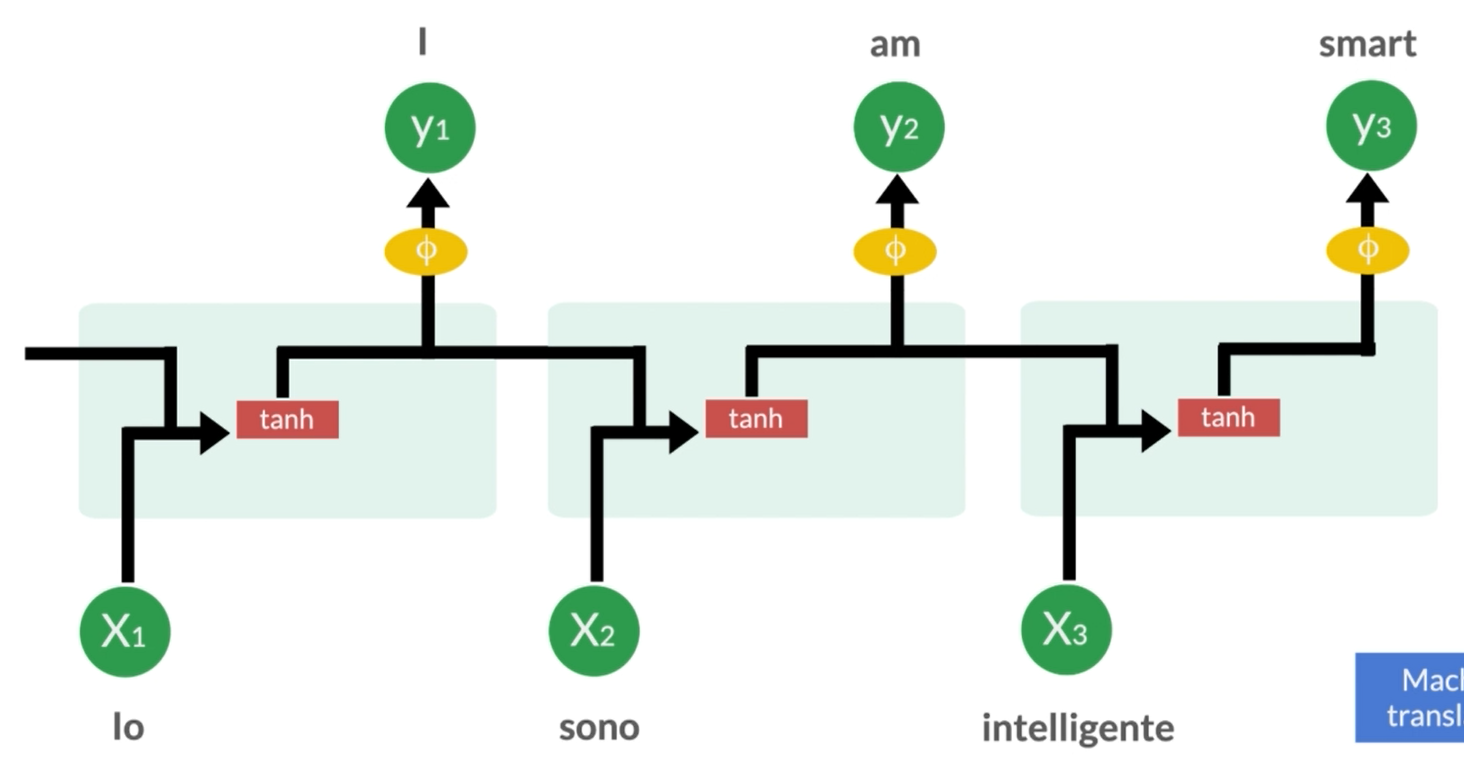
Un’altra applicazione delle RNN è nella previsione delle serie temporali. Immagina di avere dati su vendite giornaliere di un negozio. Le RNN possono essere addestrate su questi dati per cercare di prevedere le vendite future. Ciò è possibile perché le RNN sono in grado di tenere conto delle variazioni nel tempo e delle relazioni sequenziali nei dati.
Per funzionare questo tipo di rete neurale ha feedback, il che significa che l’output di uno stadio viene utilizzato come input per il successivo. Questo feedback consente alla rete di tenere traccia delle informazioni passate.
La struttura di base di una RNN è abbastanza semplice. Immagina di avere una sequenza di input: ad esempio, le parole di una frase. Ogni parola viene elaborata uno alla volta. Ora, a ogni passo, la RNN prende in input la parola attuale e la sua “memoria” dal passaggio precedente (che potrebbe essere vuota all’inizio). Poi combina queste informazioni per produrre un output e aggiorna la sua memoria. Questo processo si ripete per ogni parola nella sequenza.
Ma c’è un problema con le RNN di base: sono inclini a "dimenticare" informazioni importanti quando la sequenza diventa lunga. Questo è noto come il problema della "sparizione del gradiente". Immagina di leggere un libro lungo: potresti dimenticare i dettagli dei primi capitoli mentre procedi.
Per risolvere questo problema, sono state sviluppate varianti più complesse delle RNN, come le Long Short-Term Memory (LSTM) e le Gated Recurrent Unit (GRU). Le LSTM risolvono il problema della sparizione del gradiente aggiungendo una “memoria a lungo termine” alla rete. Questa memoria è controllata da un meccanismo chiamato “cella LSTM”, che decide quando dimenticare o aggiornare le informazioni. Le GRU, d’altra parte, semplificano leggermente la struttura delle LSTM, ma raggiungono risultati simili.
BPTT
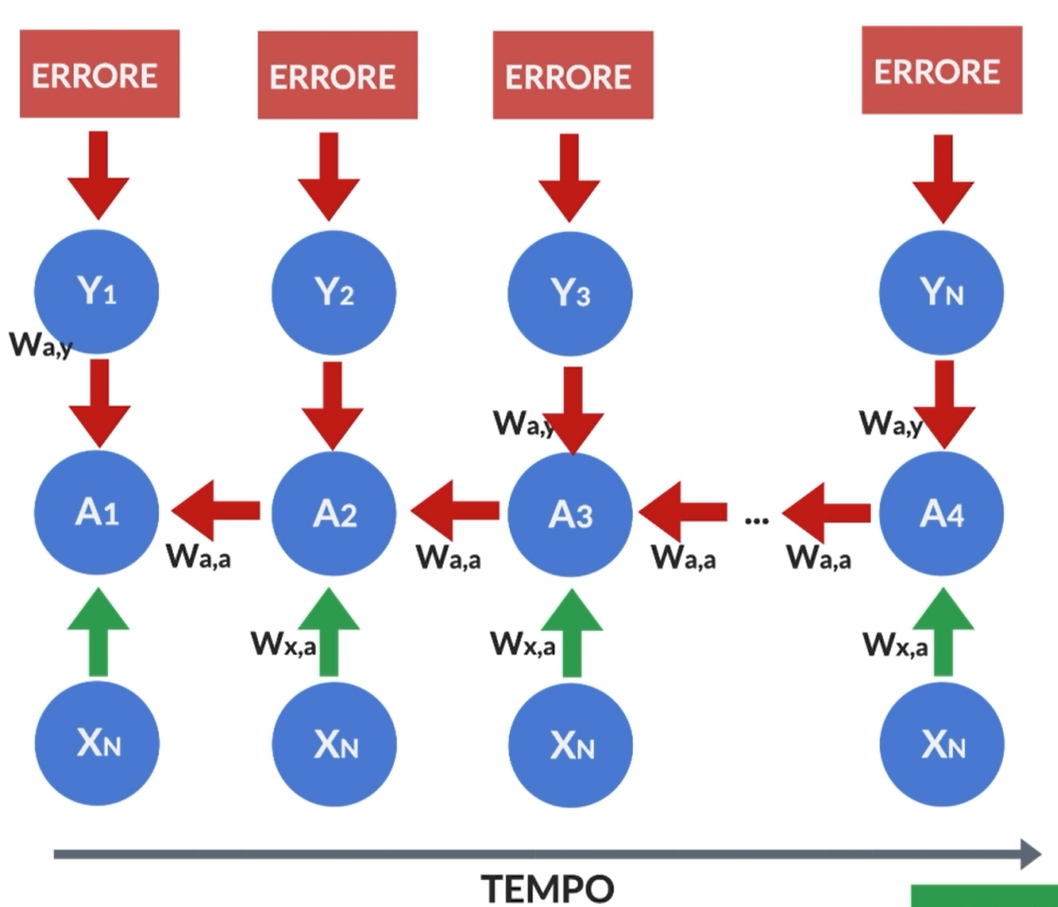
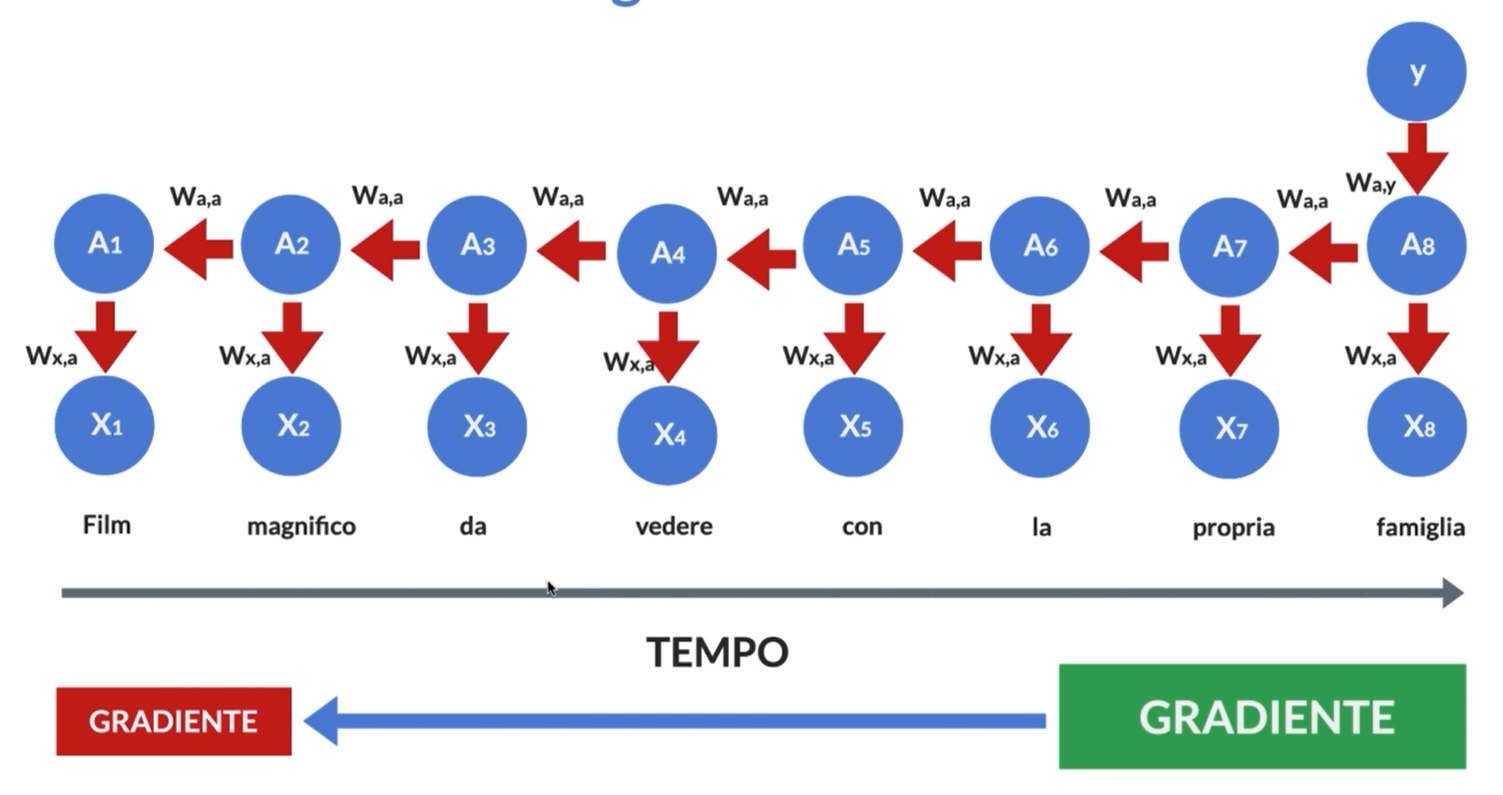
L’algoritmo di Backpropagation Through Time (BPTT) è una tecnica utilizzata per addestrare reti neurali ricorrenti (RNN) e altre architetture neurali che elaborano dati sequenziali. È una variante dell’algoritmo di backpropagation utilizzato per reti neurali feedforward, con l’aggiunta di un componente temporale a causa della natura sequenziale dei dati.
Per comprendere il funzionamento del BPTT, è importante avere una solida comprensione di come funzionano le RNN. Le RNN elaborano sequenze di dati attraverso una serie di passaggi, mantenendo una sorta di “memoria” o “stato nascosto” che tiene traccia delle informazioni precedenti. Questo stato nascosto viene aggiornato ad ogni passo temporale, consentendo alla rete di tenere conto delle informazioni storiche durante l’elaborazione di nuovi dati.
Il BPTT sfrutta questa struttura sequenziale delle RNN per addestrarle. L’obiettivo dell’addestramento è minimizzare una funzione di perdita che misura la discrepanza tra l’output previsto dalla rete e l’output desiderato. L’algoritmo di backpropagation viene utilizzato per calcolare il gradiente di questa funzione di perdita rispetto ai parametri della rete, consentendo di aggiornare i pesi in modo da ridurre l’errore di predizione.
Il BPTT si svolge in due fasi principali: il passaggio in avanti (forward pass) e il passaggio all’indietro (backward pass). Durante il passaggio in avanti, la rete elabora la sequenza di input e calcola l’output previsto. Durante il passaggio all’indietro, il gradiente della funzione di perdita rispetto ai parametri della rete viene calcolato utilizzando la regola della catena e quindi i pesi vengono aggiornati di conseguenza.
Oltre al problema della sparizione del gradiente c’è la necessità di bilanciare la trade-off tra memoria e efficienza computazionale. Poiché le RNN mantengono uno stato nascosto per ogni passaggio temporale, possono diventare computazionalmente costose quando si lavora con sequenze lunghe o ad alta risoluzione. Questo può richiedere tecniche come il “truncation” del passaggio temporale o l’utilizzo di minibatch per rendere l’addestramento più efficiente.
Il processo di addestramento con BPTT richiede diverse iterazioni attraverso l'intero set di dati di addestramento, durante le quali vengono eseguiti il passaggio in avanti e il passaggio all'indietro per ogni sequenza di input. Durante il passaggio in avanti, i dati di input vengono elaborati e l'output previsto viene confrontato con l'output desiderato per calcolare la perdita. Durante il passaggio all'indietro, il gradiente della perdita rispetto ai parametri della rete viene calcolato e utilizzato per aggiornare i pesi tramite un algoritmo di ottimizzazione come la discesa del gradiente stocastica.
LSTM

Le Long Short-Term Memory (LSTM) sono un tipo speciale di rete neurale ricorrente (RNN) progettata per gestire meglio il problema della “sparizione del gradiente” e catturare relazioni a lungo termine nei dati sequenziali.
Le LSTM contengono "unità di memoria" specializzate che sono progettate per mantenere e aggiornare informazioni a lungo termine. Queste unità di memoria sono chiamate "celle LSTM". Ogni cella LSTM ha tre porte principali: la porta di ingresso (input gate), la porta di uscita (output gate) e la porta di dimenticanza (forget gate). Queste porte controllano il flusso delle informazioni nella cella LSTM.
Durante il processo di elaborazione dei dati sequenziali, le LSTM prendono in input un vettore di dati e lo passano attraverso una serie di celle LSTM. Ogni cella LSTM decide quali informazioni mantenere nella sua memoria a lungo termine, quali informazioni aggiornare e quali informazioni dimenticare in base ai segnali ricevuti dalle porte.
La porta di ingresso decide quali nuove informazioni devono essere aggiunte alla memoria della cella LSTM. Questa decisione viene presa utilizzando una funzione sigmoide che determina quali elementi del vettore di input devono essere attivati.
La porta di dimenticanza decide quali informazioni attualmente memorizzate nella cella LSTM devono essere dimenticate. Questa decisione viene presa utilizzando una funzione sigmoide che determina quali elementi della memoria della cella devono essere cancellati.
La porta di uscita determina quali informazioni devono essere generate come output dalla cella LSTM. Questa decisione viene presa utilizzando una combinazione di una funzione sigmoide e una funzione tangente iperbolica che combinano le informazioni attualmente memorizzate nella cella LSTM con il nuovo input per produrre l’output.
GRU
Le Gated Recurrent Unit (GRU) sono un’altra variante delle reti neurali ricorrenti (RNN), sviluppate per superare alcuni dei limiti delle RNN standard, come il problema della sparizione del gradiente e la complessità computazionale delle Long Short-Term Memory (LSTM).
Le GRU sono simili alle LSTM, ma hanno una struttura leggermente più semplice. Anche se entrambe le architetture utilizzano "porte" per regolare il flusso di informazioni all'interno della rete, le GRU hanno solo due porte principali: la porta di reset (reset gate) e la porta di aggiornamento (update gate).
Durante il processo di elaborazione dei dati sequenziali, le GRU prendono in input un vettore di dati e lo passano attraverso una serie di unità GRU. Ogni unità GRU decide quali informazioni mantenere e quali informazioni aggiornare nella sua memoria in base ai segnali ricevuti dalle porte di reset e di aggiornamento.
La porta di reset decide quali informazioni del passato devono essere dimenticate e quali devono essere conservate per il futuro. Questa decisione viene presa utilizzando una funzione sigmoide che determina quali elementi della memoria della GRU devono essere azzerati.
La porta di aggiornamento determina quanto delle informazioni attualmente memorizzate nella GRU devono essere aggiornate con le nuove informazioni. Questa decisione viene presa utilizzando una funzione sigmoide che determina quanto delle informazioni attualmente memorizzate devono essere conservate.
Le GRU differiscono dalle LSTM principalmente perché non hanno una “cella di memoria” separata e una “porta di uscita”. Invece, la porta di aggiornamento decide direttamente quanto delle informazioni attualmente memorizzate devono essere conservate e quanto devono essere aggiornate con le nuove informazioni.
Un’altra caratteristica distintiva delle GRU è che sono più efficienti computazionalmente rispetto alle LSTM, poiché hanno meno parametri e meno complessità strutturale. Questo le rende più veloci da addestrare e più facili da utilizzare in applicazioni pratiche con grandi quantità di dati ma meno precise rispetto alle LSTM in quanto queste tendono a ricordare sequenze più lunghe.
Esempi
Certamente, le reti neurali ricorrenti (RNN) e le loro varianti come le LSTM e le GRU hanno una vasta gamma di applicazioni in diversi settori. Ecco cinque applicazioni principali:
- Elaborazione del linguaggio naturale (NLP): Le RNN sono estremamente efficaci nell’analisi del testo e nella generazione di linguaggio naturale. Possono essere utilizzate per compiti come il riconoscimento delle entità nomate (NER), la classificazione del sentiment nelle recensioni, la traduzione automatica e la generazione di testi e il sentiment analysis. Ad esempio, molti motori di ricerca, assistenti vocali e software di analisi del testo si affidano alle RNN per comprendere e generare linguaggio umano.
- Riconoscimento della scrittura a mano: Le RNN sono utilizzate nei sistemi di riconoscimento della scrittura a mano, dove possono convertire i caratteri scritti a mano in testo digitale. Questo è utile in applicazioni come il riconoscimento di indirizzi su pacchetti, la digitalizzazione di documenti scritti a mano e la creazione di firme digitali.
- Previsione delle serie temporali: Le RNN sono efficaci nel modellare e prevedere serie temporali, come dati meteorologici, dati finanziari, vendite al dettaglio e traffico web. Possono catturare le complesse relazioni sequenziali nei dati e fornire previsioni accurate. Questo è utile per la pianificazione aziendale, la gestione delle risorse e la previsione delle tendenze di mercato.
- Riconoscimento vocale: Le RNN sono ampiamente utilizzate nei sistemi di riconoscimento vocale, dove possono convertire il parlato in testo. Questa tecnologia è presente in assistenti virtuali come Siri di Apple, Alexa di Amazon e Google Assistant. Le RNN consentono a questi sistemi di comprendere e rispondere in modo efficace alle richieste vocali degli utenti.
- Generazione di sequenze creative: Le RNN possono essere utilizzate per generare sequenze creative, come testi, musica e immagini. Ad esempio, le RNN possono essere addestrate su grandi corpi di testo e poi utilizzate per generare nuovi articoli, poesie o persino script cinematografici. Allo stesso modo, possono essere addestrate su composizioni musicali esistenti per creare nuove melodie originali.