Quando costruiamo un modello di machine learning, uno dei passaggi fondamentali è capire quanto bene il modello funzionerà su dati che non ha mai visto prima. Questo è cruciale perché vogliamo essere sicuri che il nostro modello possa fare previsioni accurate anche su nuovi dati, non solo quelli usati per addestrarlo. La valutazione delle prestazioni è comoda sia per sapere come sta andando il modello che per trovare gli iperparametri ottimali: se ho una metrica di valutazione posso sapere se un modello con gli iperparametri X funziona meglio o peggio di uno con gli iperparametri Y.
Metriche
Per confrontare modelli differenti, dobbiamo decidere le metriche da impiegare per misurarne le prestazioni.
Prestazioni durante l’addestramento
Un modello di machine learning può incorrere in due problemi principali: underfitting (elevato bias) e overfitting (elevata varianza). L’underfitting si verifica quando il modello è troppo semplice e non è in grado di catturare la complessità dei dati di addestramento. Al contrario, l’overfitting si verifica quando il modello è troppo complesso e si adatta troppo bene ai dati di addestramento, perdendo la capacità di generalizzare su nuovi dati.
Trovare un equilibrio tra bias e varianza è fondamentale per garantire che il nostro modello sia in grado di generalizzare bene su nuovi dati non visti, cioè di mantenere prestazioni ottimali su dati al di fuori del set di addestramento. Bias e varianza sono due concetti agli opposti in quanto per migliorare il primo bisogna aumentare la complessità del modello mentre per aumentare il secondo ridurre la complessità. L'obiettivo è trovare quindi un equilibrio dove il modello ha una complessità sufficiente da catturare le relazioni importanti nei dati (riducendo il bias) senza essere troppo sensibile alle fluttuazioni casuali nei dati di addestramento (riducendo la varianza). Un modello con un buon equilibrio tra bias e varianza avrà prestazioni ottimali sui dati di test, garantendo una buona capacità di generalizzazione su nuovi dati non visti.
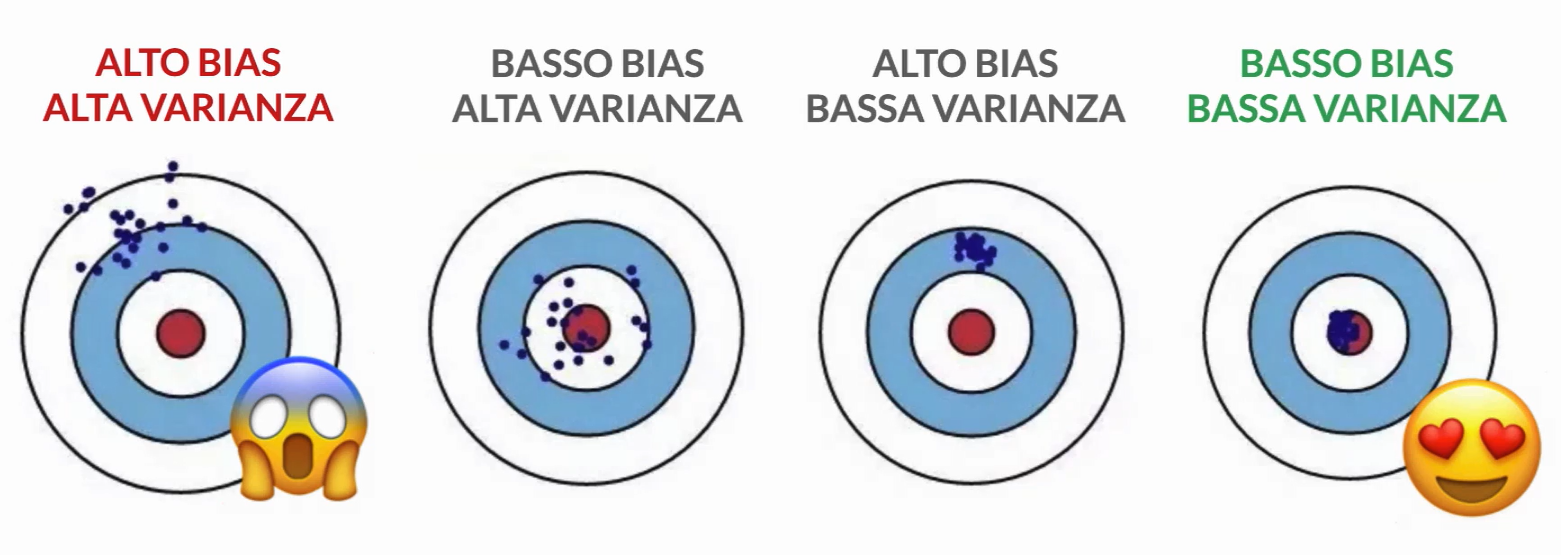
Bias
Il bias, la discrepanza, misura quanto distanti sono le previsioni rispetto ai valori corretti in generale, se ricostruiamo il modello più volte su dataset di addestramento differenti; il bias misura l’errore sistematico che non è legato alla casualità. Un modello con alto bias potrebbe non essere abbastanza complesso da catturare la complessità dei dati (underfitting), portando a una sottostima o una sovrastima sistematica delle previsioni rispetto alla realtà. Ridurre il bias di un modello implica aumentare la sua complessità, consentendo al modello di apprendere più dettagli dai dati di addestramento.
Varianza
La varianza misura la sensibilità del modello alla casualità nei dati di addestramento, in particolare la variazione nelle predizioni utilizzando diverse parti del dataset. Un modello con alta varianza è troppo complesso e tende ad adattarsi eccessivamente ai dettagli del set di addestramento, perdendo la capacità di generalizzare bene ai dati di test (Overfitting). Ridurre la varianza del modello implica ridurne la complessità, limitando la sua capacità di adattarsi troppo ai dati di addestramento.
Prestazioni sui dati di test
Classificazione
Accuratezza
L’accuratezza è la percentuale di predizioni corrette fatte dal modello, quindi la proporzione tra le istanze classificate correttamente e quelle classificate in modo errato. E’ la metrica più utilizzata.
Errore
L’errore è la percentuale di predizioni errate fatte dal modello.
Precisione
La precisione è una misura della precisione del modello quando fa una predizione positiva. Misura quindi la proporzione di predizioni positive corrette rispetto a tutte le predizioni positive fatte dal modello.
Recall
Il richiamo, o recall, è una misura della sensibilità del modello: misura la proporzione di predizioni positive corrette rispetto a tutte le istanze effettivamente positive nel dataset
F1-score
L’F1-score è una misura che tiene conto sia della precisione che del recall. È la media ponderata tra precisione e richiamo e fornisce una singola misura del bilanciamento tra precisione e recall.
Esempio
Supponiamo di avere un dataset di 1000 mail di cui vogliamo fare una classificazione binaria tra spam e non spam. Assumo una classificazione come vera positiva se è stata rilevata come spam e la mail era effettivamente spam.
Nel nostro dataset, abbiamo un totale di 1000 e-mail. Di queste:
- Mail Spam: Ci sono 100 e-mail classificate come spam.
- Mail Non Spam: Le restanti 900 e-mail non sono considerate spam.
Supponiamo che il nostro modello di classificazione abbia fatto le seguenti previsioni:
- Ha identificato correttamente 80 e-mail come spam (True Positives).
- Ha identificato erroneamente 20 e-mail non spam come spam (False Positives).
- Ha identificato correttamente 870 e-mail come non spam (True Negatives).
- Ha identificato erroneamente 30 e-mail spam come non spam (False Negatives).
Ora possiamo procedere con i calcoli delle metriche:
Precisione:
La precisione del modello è l’80%.
Richiamo (Recall):
Il richiamo del modello è di circa il 72.73%.
Errore:
L’errore del modello è del 5%.
Accuratezza:
Quindi, l’accuratezza del modello è del 95%.
Regressione
Mean Absolute Error
La MAE (Mean Absolute Error) è una misura della discrepanza media tra le previsioni di un modello e i valori osservati nei dati di test. Calcola la media delle differenze assolute tra le previsioni e i valori reali, senza considerare la direzione degli errori. E’ la metrica più semplice ed utilizzata per i classificatori.
Algoritmi di valutazione delle prestazioni
Convalida incrociata holdout
La convalida incrociata holdout è una tecnica utilizzata nell’addestramento e nella valutazione dei modelli di machine learning per valutare le loro prestazioni. È particolarmente utile quando abbiamo un dataset limitato e dobbiamo massimizzare l’utilizzo dei dati disponibili.
Immagina di avere un insieme di dati che vuoi utilizzare per addestrare un modello di machine learning. Tuttavia, non vuoi utilizzare l’intero set di dati per l’addestramento, perché devi anche valutare le prestazioni del modello su dati che non ha mai visto prima. Invece di dividere il tuo set di dati in due parti, una per l’addestramento e una per la valutazione, utilizzando la convalida incrociata holdout, suddividerai il tuo set di dati in tre parti: set di addestramento, set di convalida e set di test.
Set di Addestramento: Il set di addestramento è utilizzato per addestrare il modello. Qui, il modello impara dai dati, cerca di individuare i modelli e le relazioni nei dati per fare previsioni in futuro. Questo set di dati dovrebbe rappresentare una buona rappresentazione di tutti i possibili scenari che il modello potrebbe incontrare.
Set di Convalida: Il set di convalida è utilizzato per ==valutare le prestazioni del modello e ottimizzare i suoi Iperparametri==. Gli iperparametri sono come “impostazioni” del modello che possono essere regolati per migliorarne le prestazioni. Ad esempio, nel caso di un algoritmo di Classificazione, un iperparametro potrebbe essere il numero di alberi in un modello di Random Forests. Utilizzando il set di convalida, possiamo testare diverse configurazioni di questi iperparametri e scegliere quella che offre le migliori prestazioni.
Set di Test: Il set di test è utilizzato per valutare le prestazioni finali del modello, dopo che è stato addestrato e ottimizzato utilizzando il set di addestramento e il set di convalida. Questo set di dati dovrebbe rappresentare una vera misura delle prestazioni del modello su dati non visti. L'idea è che, se il modello ha generalizzato bene dai dati di addestramento e di convalida al set di test, allora sarà in grado di fare previsioni accurate su nuovi dati che potrebbero essere raccolti in futuro.
Ora, vediamo come utilizziamo la convalida incrociata holdout per valutare le prestazioni del modello.
- Dividi il tuo set di dati in tre parti: addestramento, convalida e test.
- Addestra il modello utilizzando il set di addestramento.
- Utilizza il set di convalida per valutare le prestazioni del modello e ottimizzare i suoi iperparametri.
- Dopo aver trovato la migliore configurazione degli iperparametri, addestra il modello utilizzando l’intero set di addestramento (addestramento + convalida).
- Valuta le prestazioni finali del modello utilizzando il set di test.
Questa tecnica ci consente di utilizzare al meglio i nostri dati, poiché utilizziamo sia il set di addestramento che quello di convalida per addestrare e ottimizzare il modello, mentre il set di test rimane isolato per valutare le prestazioni finali. Uno svantaggio del metodo holdout è il fatto che la stima delle prestazioni è sensibile al modo in cui suddividiamo il set di addestramento fra i sottoinsiemi di addestramento e convalida; la stima varierà per campioni di dati differenti.
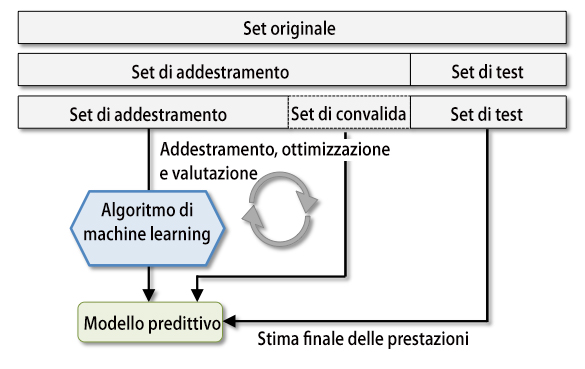
Una volta che siamo soddisfatti dei parametri, possiamo stimare l’errore di generalizzazione dei modelli sul dataset di test.
Convalida incrociata k-fold
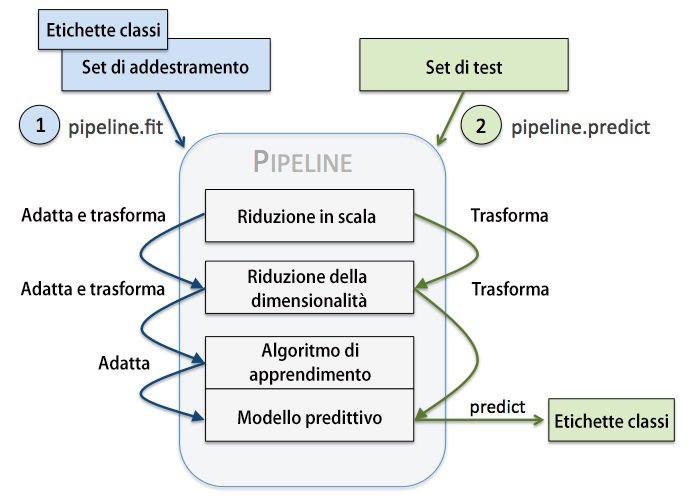
La convalida incrociata k-fold è una tecnica di valutazione dei modelli di machine learning che permette di ottenere stime più accurate delle prestazioni del modello rispetto alla convalida incrociata holdout, specialmente quando il dataset è di dimensioni limitate.
Immagina di avere un insieme di dati che vuoi utilizzare per addestrare e valutare un modello di machine learning. La convalida incrociata k-fold prevede di dividere il tuo set di dati in k "fold" (sottogruppi) di dimensioni simili. Un fold è semplicemente un sottoinsieme dei tuoi dati. Tipicamente, k viene scelto in base alla dimensione del dataset e può variare da 3 a 10, ad esempio.
Passi per la convalida incrociata k-fold:
- Dividi il dataset: Dividi il tuo set di dati in k sottogruppi (fold) di dimensioni simili.
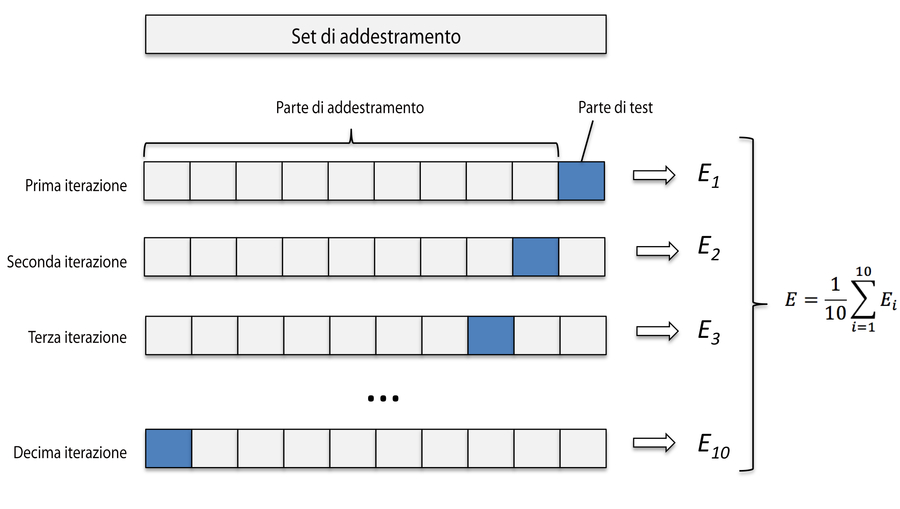
- Addestramento e Valutazione: Itera attraverso ogni fold e utilizzalo una volta come set di test, mentre gli altri k-1 fold vengono combinati per formare il set di addestramento. Ad esempio, se hai scelto k = 5 (5-fold cross-validation), allora addestrerai il tuo modello 5 volte, usando ogni volta un diverso fold come set di test.
- Valutazione delle Prestazioni: Per ogni iterazione, valuta le prestazioni del modello utilizzando il fold corrente come set di test. Questo ti darà k valutazioni delle prestazioni del modello.
- Calcolo della Media: Calcola la media delle valutazioni delle prestazioni ottenute dalle k iterazioni. Questa sarà la stima finale delle prestazioni del modello.
Utilizzando la convalida incrociata k-fold, ogni punto dati viene utilizzato sia per l’addestramento che per la valutazione del modello, garantendo che tutti i dati siano utilizzati per entrambi i compiti. Questo è particolarmente utile quando hai un set di dati limitato e vuoi massimizzare l’utilizzo dei dati disponibili.
Un vantaggio aggiuntivo della convalida incrociata k-fold è che ci consente di valutare le prestazioni del modello in modo più stabile rispetto alla convalida incrociata holdout. Poiché le valutazioni delle prestazioni vengono calcolate utilizzando k iterazioni indipendenti, riduciamo il rischio di ottenere valutazioni distorte a causa di una particolare suddivisione dei dati.
Una volta che abbiamo trovato i valori soddisfacenti degli iperparametri, possiamo riaddestrare il modello sull’intero set di e ottenere una stima finale delle prestazioni utilizzando il set di test indipendente.
Convalida incrociata k-fold stratificata
Può fornire migliori stime di bias e varianza, specialmente nei casi di proporzioni differenti fra le classi.
Strumenti diagnostici per migliorare le prestazioni
Curve di apprendimento
Talvolta basta raccogliere più campioni di addestramento per ridurre il grado di overfitting. Tuttavia, all’atto pratico, spesso può essere molto costoso o addirittura impossibile raccogliere ulteriori dati. Tracciando la precisione di addestramento e convalida del modello come funzioni delle dimensioni del set di addestramento, possiamo individuare con maggiore facilità se il modello soffre di elevata varianza o elevato bias e se la raccolta di ulteriori dati possa aiutare a risolvere questo problema
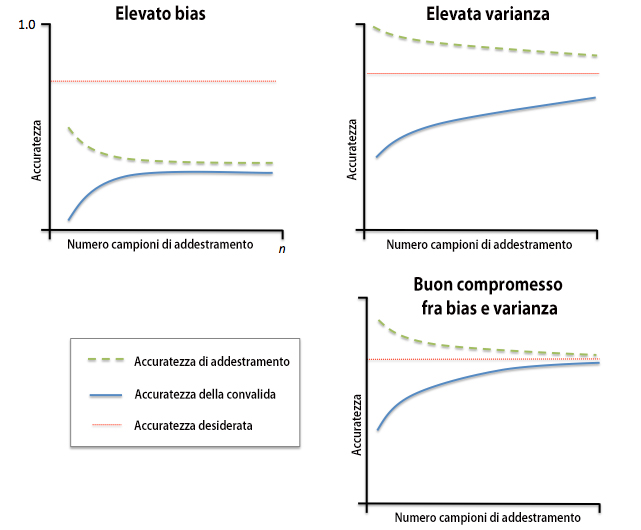
Elevato bias
Il grafico in alto a sinistra mostra un modello con elevato bias. Questo modello ha una scarsa accuratezza sia di addestramento sia di convalida incrociata (underfitting). Per risolvere questo problema, in genere si aumenta il numero di parametri del modello, per esempio raccogliendo o costruendo ulteriori caratteristiche e riducendo il grado di regolarizzazione, per esempio nei classificatori SVM o a regressione logistica.
Elevata varianza
Il grafico in alto a destra mostra un modello che soffre di elevata varianza, il che è indicato dalla distanza troppo ampia fra l’accuratezza di addestramento e l’accuratezza di convalida incrociata. Questo è il problema dell’Overfitting e le tecniche per risolverlo sono discusse in tale pagina.
Esempio
Per esempio nella creazione di un Decision tree maggiore è la profondità dell’albero maggiore sarà l’aderenza di questo ultimo ai dati del modello, portando quindi a overfit. Se invece la profondità è troppo ridotta il sistema non funzionerà nemmeno con i dati del training, causando overfit.
Quello che voglio è trovare il minimo nella curva di validazione come si vede dalla figura sotto.
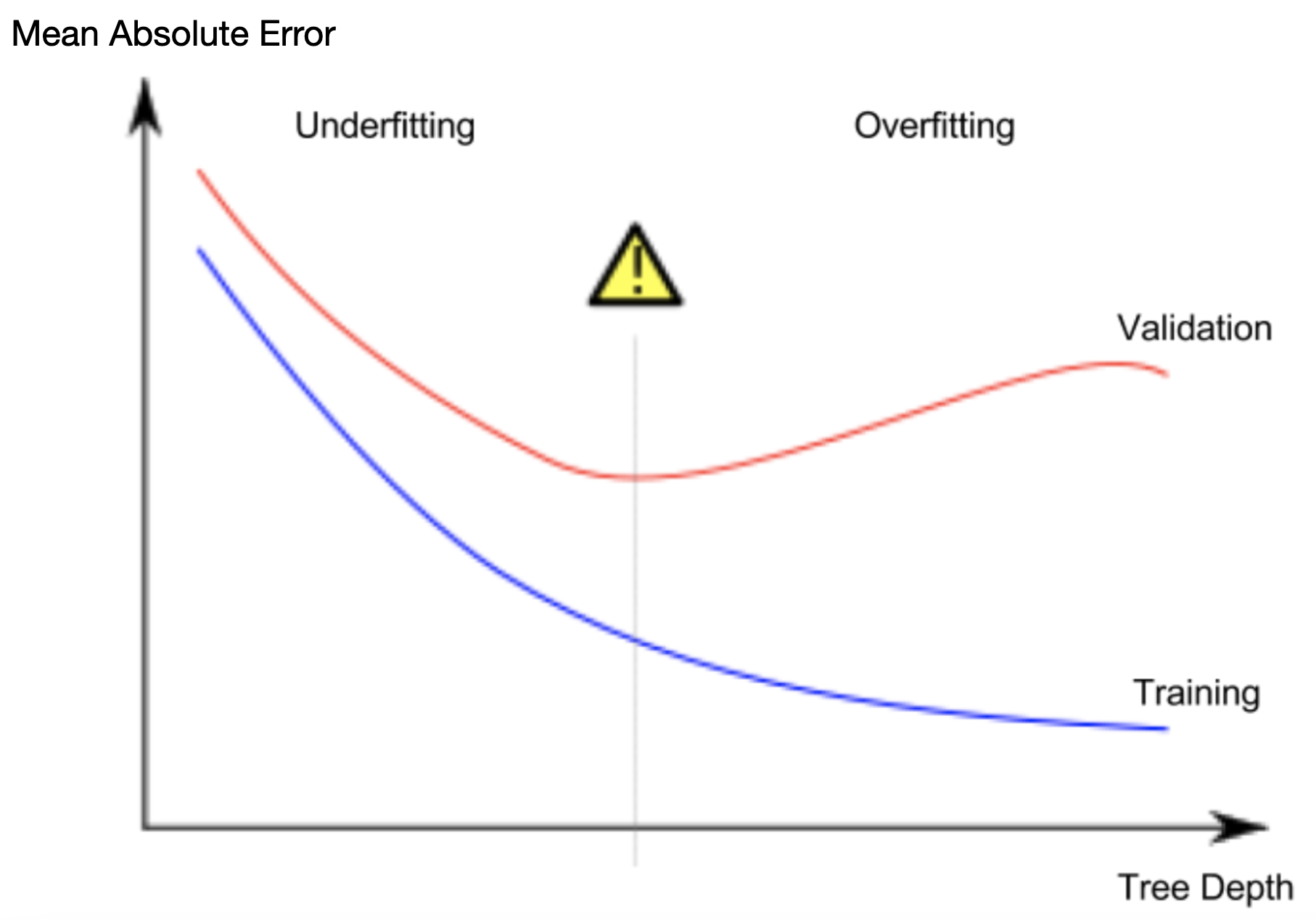
Curve di convalida
Le curve di convalida sono legate alle curve di apprendimento, ma invece di tracciare l’accuratezza di addestramento di test in funzione delle dimensioni del campione, interveniamo sui parametri del modello, per esempio il parametro di regolarizzazione inversa C nella regressione logistica.
Matrice di confusione
Grafici ROC
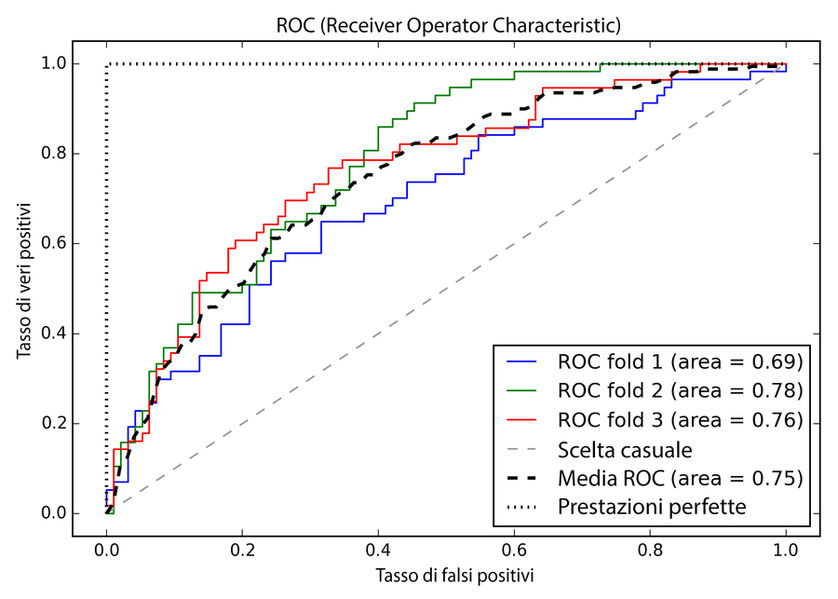
I grafici ROC (Receiver Operator Characteristic) sono strumenti utili per la selezione dei modelli di classificazione sulla base delle loro prestazioni rispetto ai tassi di falsi positivi e veri positivi, che vengono calcolati spostando la soglia di decisione del classificatore. La diagonale di un grafico ROC può essere interpretata come l’indicazione casuale. I modelli di classificazione che rientrano sotto la diagonale sono considerati peggiori rispetto alla scelta casuale. Un classificatore perfetto si collocherebbe all’angolo superiore sinistro del grafico, con un tasso di veri positivi pari a 1 e un tasso di falsi positivi pari a 0. Sulla base della curva ROC, possiamo quindi calcolare la cosiddetta area sotto la curva (AUC – area under the curve), per caratterizzare le prestazioni del modello di classificazione.