Un algoritmo di Random Forest è una tecnica avanzata di machine learning che si basa sull’idea di combinare molteplici Decision tree in un’unica “foresta” per fare previsioni più accurate e robuste.
Immagina di avere una vasta gamma di esperti, ognuno specializzato in un determinato tipo di previsione. Ognuno di questi esperti ha una visione unica del problema e offre un contributo diverso. La Random Forest opera in modo simile, creando una "foresta" di alberi decisionali, ognuno dei quali è addestrato su un sottoinsieme casuale dei dati e delle caratteristiche.
Algoritmo
Per capire come funziona, iniziamo con la creazione di ogni albero decisionale nella foresta. L’algoritmo di Random Forest seleziona casualmente (bootstrap) un sottoinsieme dei dati di addestramento e delle caratteristiche di dimensioni n per ogni albero. Questo significa che ogni albero viene addestrato su un campione diverso dei dati, rendendoli indipendenti l'uno dall'altro.
Per ogni nodo:
- Selezionare casualmente d caratteristiche senza reinserimento;
- Suddividere il nodo utilizzando la caratteristica che fornisce la migliore suddivisione sulla base della funzione obiettivo, per esempio massimizzando il guadagno informativo.
- Ripetere per k volte i passi 1 e 2. Aggregare le previsioni di ciascun albero per assegnare l’etichetta della classe sulla base di un voto a maggioranza.
Una volta addestrati tutti gli alberi decisionali, vengono utilizzati per fare previsioni su nuovi dati. Ogni albero fornisce la sua previsione e la previsione finale viene ottenuta per votazione o mediante la media delle previsioni di tutti gli alberi.
Vantaggi
Ci sono diversi vantaggi nell’utilizzo di un algoritmo di Random Forest. In primo luogo, è meno suscettibile all’Overfitting rispetto a un singolo albero decisionale, poiché la combinazione di molteplici alberi riduce la varianza complessiva del modello. In secondo luogo, è in grado di gestire un gran numero di caratteristiche e può essere utilizzato efficacemente anche con dati rumorosi o mancanti. Inoltre, è relativamente semplice da implementare e può essere parallelizzato per velocizzare il processo di addestramento su grandi dataset.
Svantaggi
Tuttavia, ci sono anche alcune considerazioni da tenere presente. Ad esempio, il costo computazionale può essere più elevato rispetto a un singolo albero decisionale, poiché coinvolge la costruzione e la combinazione di molti alberi. Inoltre, la comprensione delle previsioni di una Random Forest può essere più complessa rispetto a un singolo albero, poiché coinvolge la considerazione di molteplici alberi e le loro interazioni.
Esempio
Prendiamo questo esempio: dato un array di persone che sono state sul Titanic devo capire quali sono sopravvissuti a partire dalle loro caratteristiche (esempio il sesso, l’età, la classe e così via)
Assumiamo di dover decidere se questo passeggero sopravviverà
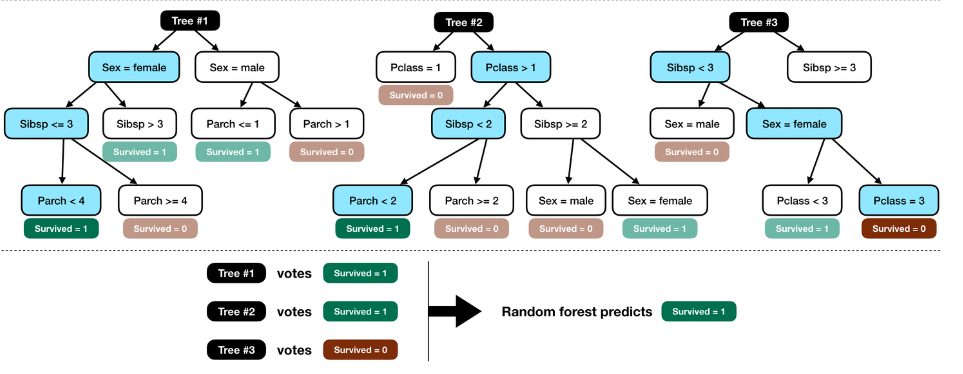
 In questo esempio costruisco 3 alberi decisionali di profondità 3 (nel mondo reale il loro numero e la loro profondità è molto maggiore ovviamente) con delle caratteristiche random.
Per esempio il primo ham in ordine, Sex, SibSp e Parch, il secondo Pclass, SibSp e Parch mentre l’ultimo ha Sibsp, Sex e Pclass.
Nel training del modello viene costruita lk’etichetta “Survived=1/0” associata ad ogni nodo.
Nell’inferenza vengono dati in pasto i dati a questi alberi e quello con più voti vince.
In questo esempio costruisco 3 alberi decisionali di profondità 3 (nel mondo reale il loro numero e la loro profondità è molto maggiore ovviamente) con delle caratteristiche random.
Per esempio il primo ham in ordine, Sex, SibSp e Parch, il secondo Pclass, SibSp e Parch mentre l’ultimo ha Sibsp, Sex e Pclass.
Nel training del modello viene costruita lk’etichetta “Survived=1/0” associata ad ogni nodo.
Nell’inferenza vengono dati in pasto i dati a questi alberi e quello con più voti vince.