Gli embeddings sono dei dati di qualsiasi genere che sono stati convertiti (da un embedding model) in degli array di numeri. Consentono ai computer di comprendere il significato delle parole in modo più sofisticato, rappresentandole come vettori ad alta dimensionalità anziché semplici stringhe di caratteri.
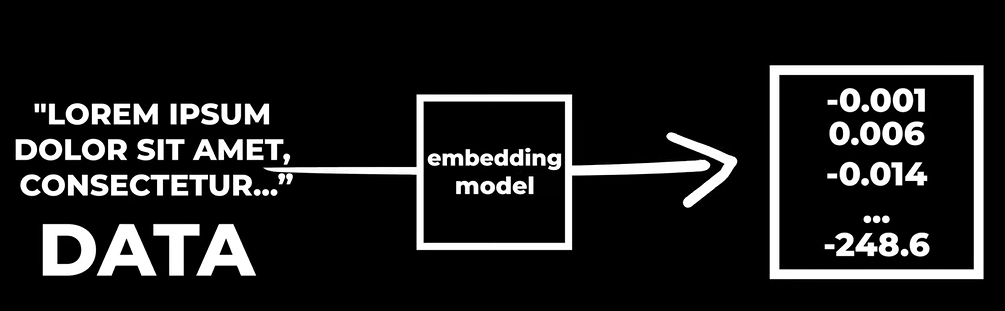
Gli embeddings funzionano mappando un oggetto in ingresso (per esempio una parola) in un punto in uno spazio ad alta dimensionalità mediante un vettore.
Gli oggetti possono essere di qualsiasi tipologia, dall’immagine al testo all’audio.
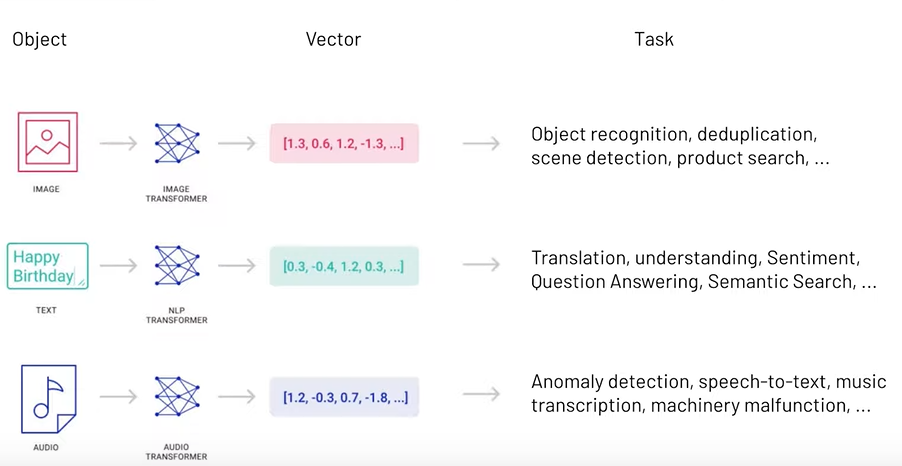
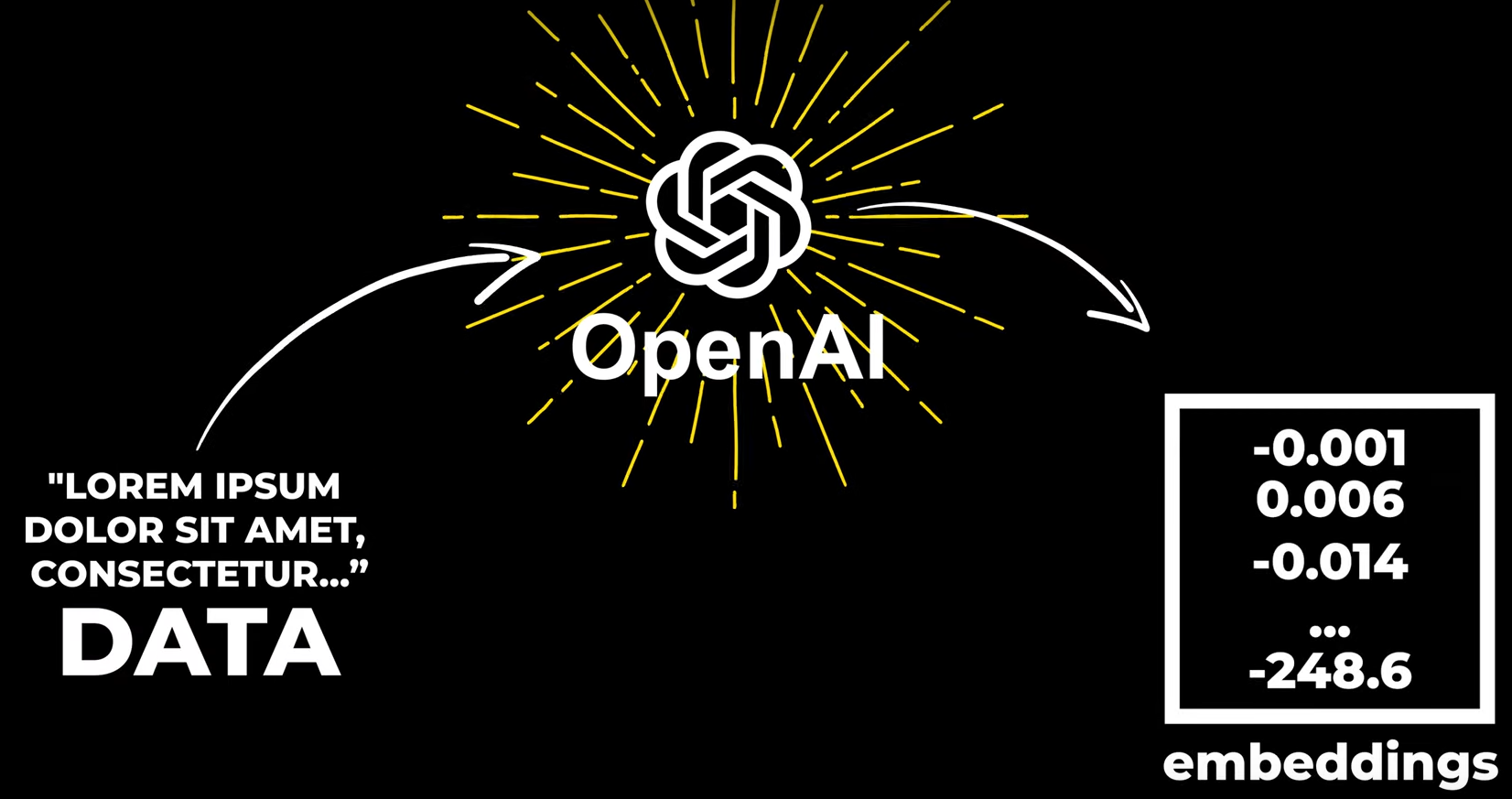
In questa immagine si vede come viene trasformata una stringa in ingresso in un vettore di numeri:
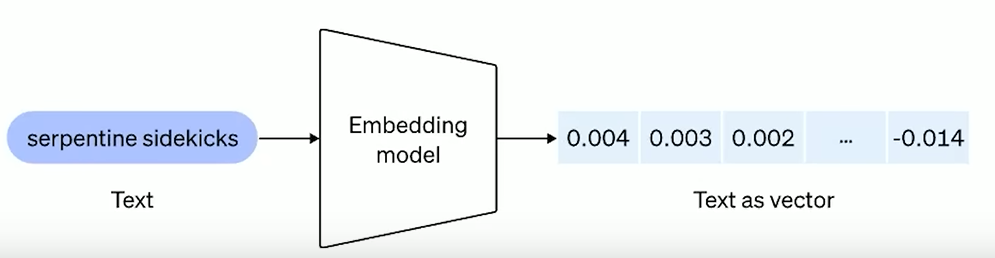 In questa immagine invece si vede come avviene lo stesso modo per una immagine:
In questa immagine invece si vede come avviene lo stesso modo per una immagine:
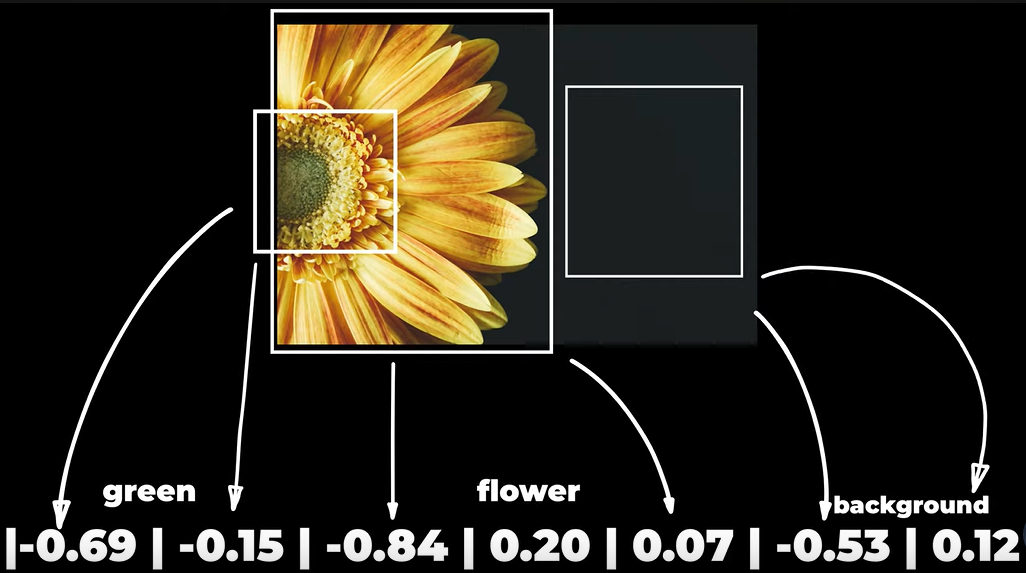
Gli embedding vengono tipicamente memorizzati in un database apposito, il Vector database: un database progettato in modo che le gli oggetti con significati simili siano posizionati vicini l'una all'altra. Ciò consente agli algoritmi di identificare relazioni tra le parole, come sinonimi o antonimi, senza necessità di regole esplicite o supervisione umana.
Semantic Memory
Gli embedding sono utilizzati spesso per aggiungere memoria ai LLM (es. memory) in modo da poter integrare la loro potenza con dei dati custom del singolo utilizzatore. Questo approccio consente al modello di apprendere relazioni tra i concetti e fare inferenze basate sulla similarità o sulla distanza tra le rappresentazioni vettoriali (vedi Cosine Similarity). Ad esempio, la memoria semantica può essere addestrata per comprendere che “Word” e “Excel” sono concetti correlati perché entrambi sono tipi di documenti e prodotti Microsoft, anche se utilizzano formati di file diversi e offrono funzionalità diverse. Questo tipo di memoria è utile in molte applicazioni, tra cui sistemi di domande e risposte, comprensione del linguaggio naturale e grafi di conoscenza.
Gli sviluppatori di software possono utilizzare modelli di embeddings pre-addestrati o addestrare il proprio modello con set di dati personalizzati. I modelli di embeddings pre-addestrati sono stati addestrati su grandi quantità di dati e possono essere utilizzati immediatamente per molte applicazioni. Modelli di embeddings personalizzati possono essere necessari quando si lavora con vocabolari specializzati o linguaggi specifici del dominio.
Esempio
Immaginatevi di trovarvi in uno spazio bidimensionale simile a una mappa italiana. Da un lato c’è Roma, dall’altro lato c’è Napoli e da un’altra parte c’è Milano. Attraverso un sistema di coordinate, come la latitudine e la longitudine, posso localizzare le città e determinare quale città è più vicina se mi trovo a Roma e voglio andare alla città più vicina, che è chiaramente Napoli in questo contesto geografico. Una città viene rappresentata da due coordinate, la latitudine e la longitudine.
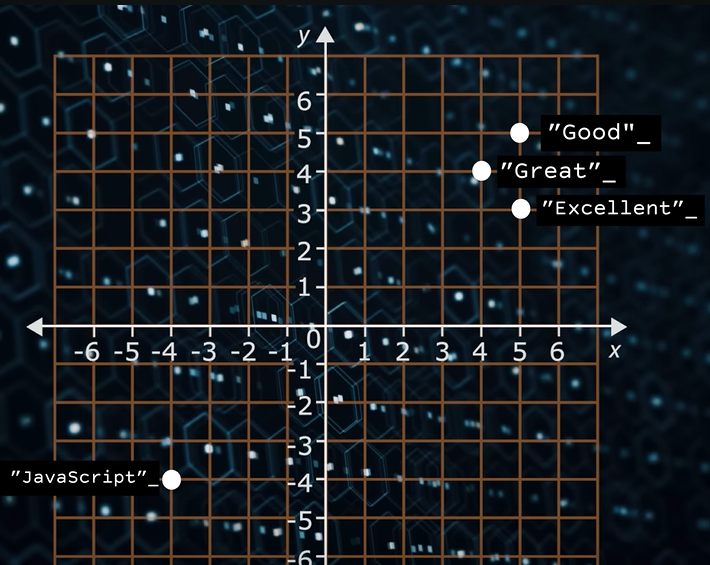
 Sempre stando nell’esempio 2D abbiamo il nostro embedder converte le stringhe in vettori come si vede dall’immagine sotto, si vede anche a occhio che i vettori sono “simili” per le parole che hanno significato semantico simile mentre molto diverse per “Javascript”
Sempre stando nell’esempio 2D abbiamo il nostro embedder converte le stringhe in vettori come si vede dall’immagine sotto, si vede anche a occhio che i vettori sono “simili” per le parole che hanno significato semantico simile mentre molto diverse per “Javascript”
 Mettendo il dato su un piano cartesiano la similarità è evidente.
Mettendo il dato su un piano cartesiano la similarità è evidente.
Ora dobbiamo fare due sforzi diversi
- Allontanarci dalla prospettiva geografica e considerare un discorso più astratto basato sul concetto di dimensioni e spazio
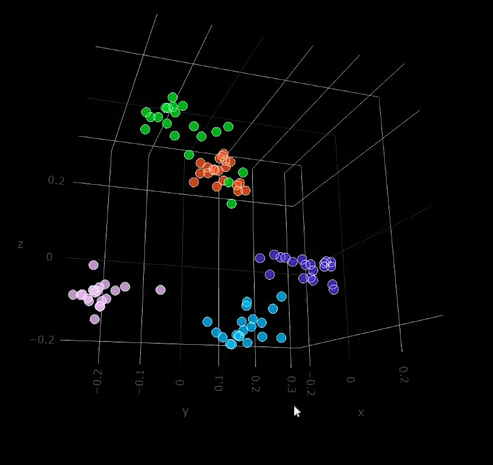
- Immaginiamo che ci siano cinquemila coordinate in questo spazio bidimensionale, che rappresentano caratteristiche personali come l’interesse per lo sport, l’amore per la letteratura e così via.
Ogni persona può essere rappresentata come un punto in questo spazio in base a queste coordinate. Misurando la distanza tra i punti, posso trovare persone con interessi simili in base alla loro vicinanza o lontananza all’interno di questo spazio geometrico. Quindi, ci siamo allontanati dalla geografia e ci siamo spostati su caratteristiche personali, ma queste misure potrebbero essere di qualsiasi tipo.
Motori per creare embeddings
Per creare un embedding a partire da del testo posso utilizzare dei modelli prefatti (il più famoso ora è text-embedding-ada-002) oppure crearmi io il mio embedding model custom.
Sia Azure OpenAI che OpenAI hanno delle comode API (reference qui)da chiamare per convertire una stringa in ingresso in un vettore di numeri.
Esempio
In questo esempio utilizzo Postman per chiamare le API di OpenAi per ottenere il vettore degli embedding della parola “Hello world”. Basta chiamare come POST questo url:
https://api.openai.com/v1/embeddings
Autorizzandolo con una API Key e passando come body raw JSON questo
{
"input": "Hello world",
"model": "text-embedding-ada-002"
}Quello che ottengo è un JSON analogo a:
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}Come si nota ottengo un array che contiene moltissimi valori numerici tra 0 e 1.
Il testo che posso passare al modello di embedding può essere molto lungo, 8191 token per ada-002 che corrispondono circa a 32k caratteri.
Applicazioni
Ecco alcuni esempi di applicazioni delle embeddings:
- Semantic Memory: Le embeddings possono essere utilizzate per creare una memoria semantica, attraverso la quale una macchina può imparare a comprendere i significati di parole e frasi e a comprendere le relazioni tra di esse.
- Elaborazione del linguaggio naturale (NLP): Le embeddings possono essere utilizzate per rappresentare parole o frasi in compiti di NLP come l’analisi del sentiment, il riconoscimento di entità nominate e la classificazione del testo.
- Sistemi di raccomandazione: Le embeddings possono essere utilizzate per rappresentare gli elementi in un sistema di raccomandazione, consentendo raccomandazioni più accurate in base alla similarità tra gli elementi.
- Riconoscimento delle immagini: Le embeddings possono essere utilizzate per rappresentare le immagini in compiti di visione artificiale come la rilevazione di oggetti e la classificazione delle immagini.
- Rilevazione delle anomalie: Le embeddings possono essere utilizzate per rappresentare i punti dati in set di dati ad alta dimensionalità, semplificando l’individuazione degli outlier o dei punti dati anomali.
- Analisi dei grafi: Le embeddings possono essere utilizzate per rappresentare i nodi in un grafo, consentendo un’analisi e una visualizzazione dei grafi più efficienti.
- Personalizzazione: Le embeddings possono essere utilizzate per rappresentare gli utenti in sistemi di raccomandazione personalizzati o motori di ricerca personalizzati.