Una rete neurale convoluzionale (CNN) è un tipo di rete neurale artificiale che si basa sull'apprendimento automatico supervisionato. Questo tipo di rete viene utilizzato principalmente per l'elaborazione delle immagini e del video, ma può essere applicato anche ad altri tipi di dati come il suono o i testi.
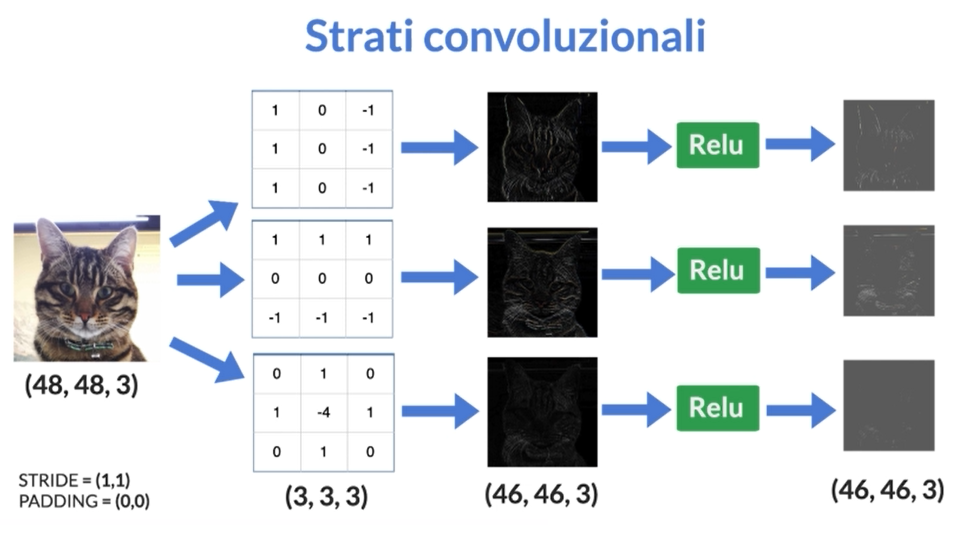
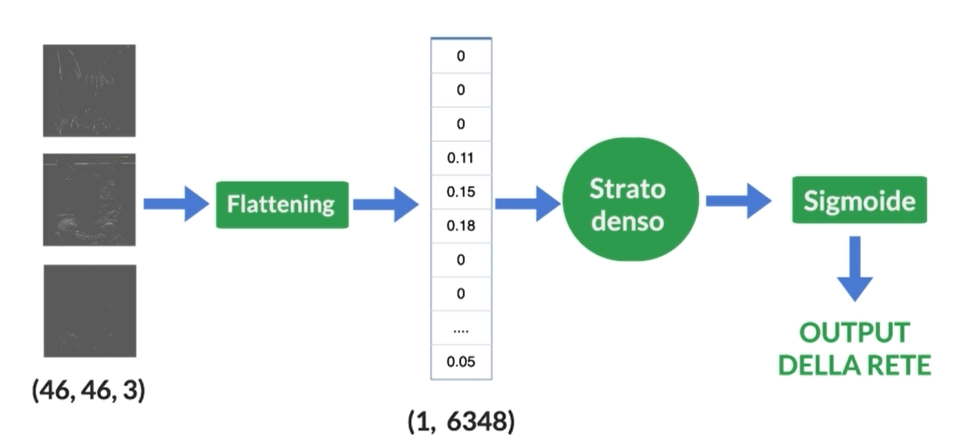
La CNN prende in input una matrice bidimensionale rappresentante un’immagine e la elabora attraverso una serie di strati convoluzionali, pooling e completamente connessi. Il primo strato della CNN è quello convoluzionale, dove vengono estratti dei filtri dalle immagini d’input per creare mappe delle caratteristiche dell’immagine stessa. Queste mappe sono poi passate attraverso uno strato di pooling che riduce le dimensioni dell’immagine mantenendo solo le informazioni più importanti.
In seguito ci sono diversi strati convoluzionali alternati a quelli di pooling fino a quando non si arriva allo strato completamente connesso finale dove avviene la classificazione dell’oggetto presente nell’immagine.
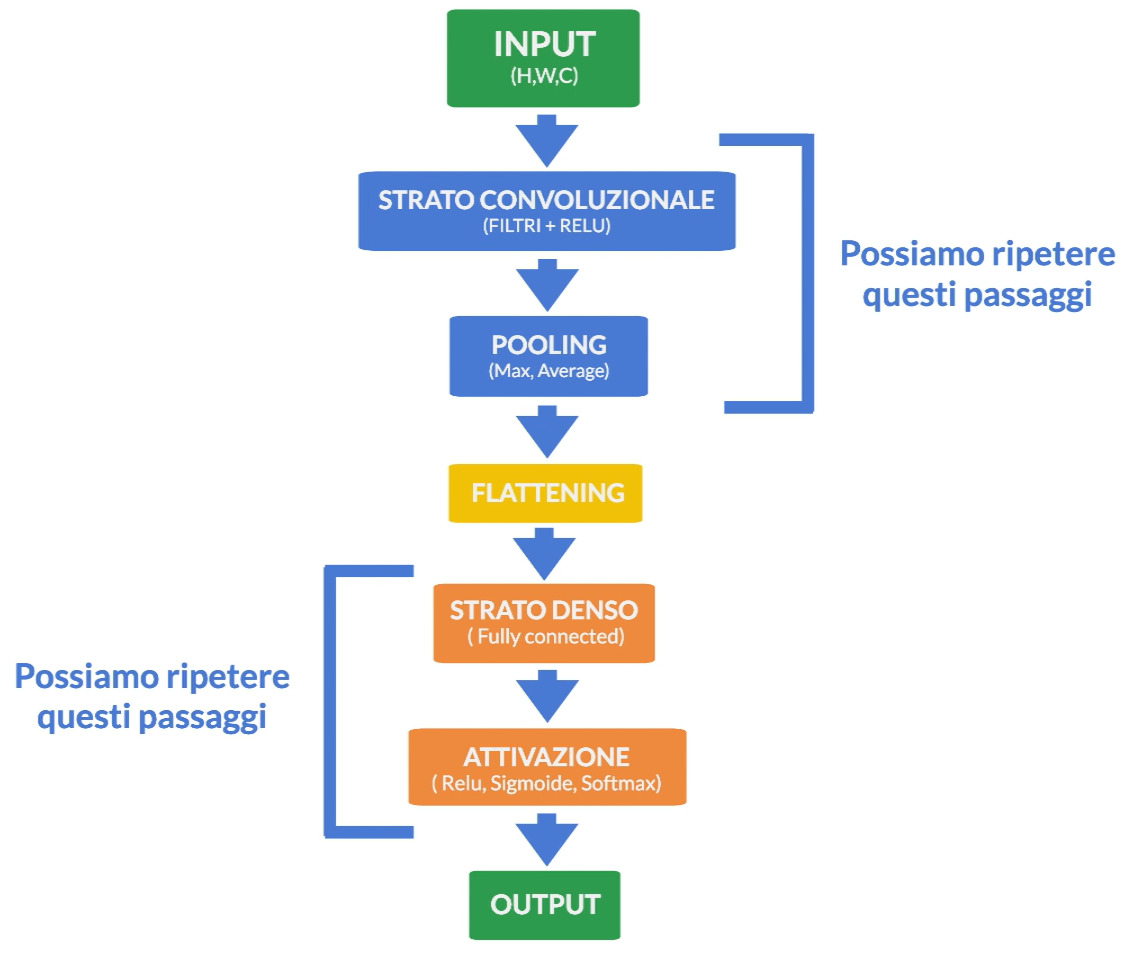
Le reti neurali convoluzionali hanno rivoluzionato il campo della visione artificiale grazie alla loro capacità di apprendere funzioni complesse dai dati grezzi senza bisogno dell’estrazione manuale delle features dall’immagine da parte degli esperti del settore. Ciò significa che possono essere utilizzate in molteplici contestualizzazioni come riconoscimento facciale, diagnosi medica tramite radiografie o scansione MRI oppure nel campo automobilistico nella guida autonoma.
Un altro aspetto importante delle CNN è la possibilità di effettuare transfer learning ovvero l’utilizzo pre-addestramento sui pesi ottenuti da altre architetture già addestrate su milioni d’image permettendo così alle nuove architetture costruite sulla base dei pesi preaddestrati miglioramenti notevoli rispetto ai modelli partiti dallo zero.
Stride e padding
Per controllare la dimensione delle uscite dei layer convoluzionali e per gestire i bordi delle immagini durante la convoluzione.
- Stride (Passo): Lo stride è un parametro che determina il numero di passi che il filtro (o kernel) compie durante l’applicazione della convoluzione sull’input. In altre parole, indica di quanti pixel il filtro si sposta alla volta mentre scorre sull’input. Ad esempio, con uno stride di 1, il filtro si sposterà di un pixel alla volta. Con uno stride di 2, il filtro salterà due pixel alla volta. Un valore di stride più grande significa una riduzione più rapida della dimensione dell’output.
- Padding (Riempimento): Il padding è l’aggiunta di pixel intorno ai bordi dell’input prima di applicare la convoluzione. Serve a gestire il problema della riduzione delle dimensioni dell’output causato dalla convoluzione. Ci sono due tipi comuni di padding:
- Valid (Senza padding): In questo caso, non viene aggiunto alcun padding all’input. Di conseguenza, la dimensione dell’output sarà inferiore rispetto all’input, poiché il filtro non può scorrere completamente sui bordi.
- Same (Padding per mantenere le dimensioni): Qui, il padding viene aggiunto in modo che l’output abbia le stesse dimensioni dell’input. Questo viene fatto aggiungendo un numero appropriato di pixel intorno ai bordi in modo che il filtro possa scorrere completamente su tutti i pixel dell’input. Ciò aiuta a mantenere le informazioni nei bordi dell’immagine durante la convoluzione.
Pooling
Il pooling è un’operazione utilizzata nelle Convolutional Neural Networks (CNN) per ridurre la dimensione spaziale (larghezza e altezza) della rappresentazione dell'immagine, mantenendo le caratteristiche più rilevanti.
In parole semplici, il pooling riduce la dimensione dell’immagine, mantenendo le informazioni più importanti. Ciò viene fatto suddividendo l’immagine in regioni sovrapposte (ad esempio, 2x2 o 3x3) e applicando una funzione di aggregazione, come il massimo (max pooling) o la media (average pooling), a ciascuna regione.
Ad esempio, se usiamo il max pooling, per ogni regione 2x2 dell’immagine, selezioniamo il valore massimo e lo manteniamo, eliminando gli altri. Questo processo riduce la dimensione dell’immagine a circa la metà, poiché stiamo prendendo solo il massimo valore da ogni 2x2 regione.
Il pooling è utile per diverse ragioni:
- Riduzione della dimensionalità: Riducendo la dimensione dell’immagine, si riducono i computi e i parametri richiesti nella rete, il che rende il modello più efficiente in termini di tempo e risorse computazionali e riduce il rischio di Overfitting.
- Invarianza alle traslazioni: Aiuta a rendere la rete neurale più robusta alle piccole variazioni spaziali nell’input, poiché le caratteristiche importanti sono conservate anche se spostate di pochi pixel.
- Permette di riconoscere il target anche in posizioni diverse dell’immagine