L’encoding “one-hot” è una tecnica per ==rappresentare le variabili categoriche che non hanno un ordinamento (variabili categoriche nominali) in modo numerico . In parole semplici, il one-hot encoding converte le categorie in vettori binari, in cui ogni categoria diventa una colonna e viene rappresentata da un 1 o un 0==.
Funzionamento
Immagina di avere una colonna chiamata “Colore” con tre categorie: Rosso, Verde e Blu. Utilizzando il one-hot encoding, questa colonna verrebbe divisa in tre colonne separate: “Rosso”, “Verde” e “Blu”. Per ogni riga del dataset, verrà assegnato un valore 1 alla colonna corrispondente al colore presente in quella riga e 0 alle altre colonne.
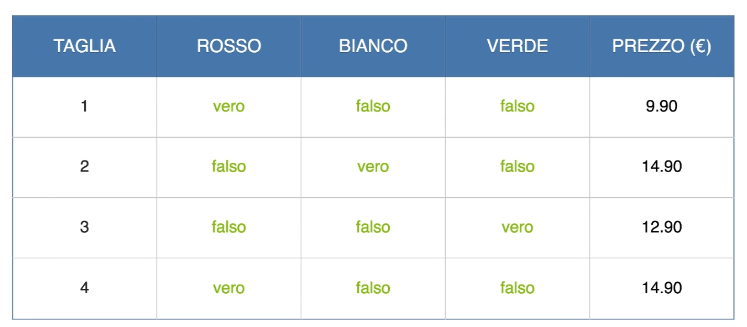
- Se una riga ha il colore “Rosso”, la colonna “Rosso” conterrà un 1 e le altre colonne conterranno 0: (1, 0, 0)
- Se una riga ha il colore “Verde”, la colonna “Verde” conterrà un 1 e le altre colonne conterranno 0: (0, 1, 0)
- Se una riga ha il colore “Blu”, la colonna “Blu” conterrà un 1 e le altre colonne conterranno 0: (0, 0, 1)
Esempi
Scikit learn
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Dataset d'esempio
# Ogni riga rappresenta [Età, Città]
data = np.array([
[25, 'Milano'],
[30, 'Roma'],
[22, 'Napoli'],
[35, 'Milano']
])
# Indici delle colonne
colonna_categorica = [1] # Colonna "Città"
colonna_numerica = [0] # Colonna "Età"
# Creazione del ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
('onehot', OneHotEncoder(), colonna_categorica), # One-hot encoding per "Città"
('passthrough', 'passthrough', colonna_numerica) # Lascia invariata "Età"
]
)
# Applicazione del ColumnTransformer
data_trasformato = preprocessor.fit_transform(data)
# Output del risultato
print(data_trasformato)Output:
[[ 1. 0. 0. 25.]
[ 0. 0. 1. 30.]
[ 0. 1. 0. 22.]
[ 1. 0. 0. 35.]]Pandas
Un modo comodo per creare queste caratteristiche fittizie tramite la codifica one-hot consiste nell’utilizzare il metodo get_dummies implementato nei pandas.
Ecco un esempio di come gestire un DataFrame rappresentante magliette con le colonne “Taglia”, “Colore” e “Prezzo” in modo che sia facilmente gestibile da un algoritmo di machine learning utilizzando Pandas.
In questo esempio, utilizzeremo il one-hot encoding per la colonna “Colore”, faremo un mapping numerico per “Taglia” mentre lasceremo il prezzo così come è in quanto è già un numero comodo.
import pandas as pd
# Creiamo un DataFrame di esempio con magliette
data = {'Taglia': ['S', 'M', 'L', 'XL', 'M'],
'Colore': ['Rosso', 'Verde', 'Blu', 'Rosso', 'Blu'],
'Prezzo': [20, 25, 30, 22, 35]}
df = pd.DataFrame(data)
# Mappiamo la taglia a un valore numerico in base all'ordine crescente
taglia_mapping = {'S': 1, 'M': 2, 'L': 3, 'XL': 4}
df['Taglia'] = df['Taglia'].map(taglia_mapping)
# Applichiamo il one-hot encoding solo alla colonna 'Colore'
df_encoded = pd.get_dummies(df, columns=['Colore'])
# Stampiamo il DataFrame elaborato
print(df_encoded)Output:
Taglia Prezzo Colore_Blu Colore_Rosso Colore_Verde
0 1 20 0 1 0
1 2 25 0 0 1
2 3 30 1 0 0
3 4 22 0 1 0
4 2 35 1 0 0