Amazon DynamoDB è un database NoSQL completamente gestito, progettato per supportare carichi di lavoro ad alte prestazioni (single digit ms indipendentemente dalla dimensione del db) e latenza bassa e prevedibile. Il sistema è stato progettato per avere prestazioni costanti ad ogni scala e dimensione. Il livello gratuito per DynamoDB offre 25 GB di spazio di archiviazione, insieme a 25 unità di capacità di scrittura e 25 unità di capacità di lettura (WCU, RCU), sufficienti per gestire 200 milioni di richieste al mese. Supporta tabelle, chiavi primarie e indici secondari per ottimizzare le query. Con funzionalità come DynamoDB Streams e capacità on-demand, il servizio è flessibile e permette di gestire grandi volumi di dati senza complessità operativa. A differenza dei database relazionali, DynamoDB non supporta un operatore JOIN: è buona norma denormalizzare il tuo modello di dati per ridurre i round trip del database e la potenza di elaborazione necessaria per rispondere alle query.
Quando usare DynamoDB
- Non è richiesta alcuna analisi sui dati
- I dati sono significativamente grandi e sono richiesti importanti SLA (Service Level Agreement). Esempio uptime garantito al 99,99%, bassa latenza e così via.
- Sono definiti e noti gli access patterns: sia oggi che nel prossimo futuro posso sapere esattamente quali sono le query di interrogazione del DB che andrò a fare. Nei DBMS relazionali, i dati possono essere interrogati in modo flessibile, ma le query sono relativamente costose e non sono scalabili in situazioni di traffico elevato. Mentre nel caso di DynamoDB, i dati possono essere interrogati in modo molto efficiente, ma solo in un numero limitato di modi.
Single Table Design
==In DynamoDB, l’idea di Single Table Design è prevalente: questo approccio si basa sull'uso di una singola tabella per memorizzare diversi tipi di entità che in un database relazionale sarebbero distribuiti in tabelle separate. La modellazione iniziale richiede una conoscenza approfondita degli access pattern, perché non c'è un sistema di join dinamico come nei relazionali: bisogna prevedere ogni possibile query in anticipo==.
Vantaggi della tabella singola
- Performance ottimizzata per le query previste:
- DynamoDB è progettato per query rapide e scalabili. Con una tabella singola, puoi ottimizzare la struttura delle chiavi (PK e SK) e usare indici secondari per coprire casi d’uso specifici, evitando join costosi.
- Ad esempio, puoi memorizzare gli utenti e i loro ordini nella stessa tabella, usando una PK come
UserIDe una SK per distinguere tra un profilo utente (PROFILE) e i suoi ordini (ORDER#001).
- Meno sovraccarico nella gestione: meno tabelle significa meno configurazioni, meno costi operativi e una gestione più semplice.
- Adatto a modelli NoSQL: dynamoDB favorisce un design basato su access pattern (come gli schemi Star o Tree nei relazionali), dove progetti il tuo schema pensando a come i dati saranno letti e non a come sono logicamente strutturati.
Componenti principali
I componenti di cui è composto un database DynamoDB sono:
- Tabelle, oggetti e attributi (analogo a tabelle, righe e colonne nel classico DBMS)
- Primary Keys
- Secondary Indexes
- Streams
Primary Keys
A differenza dei database relazionali classici nei NoSQL è fondamentale strutturare le tabelle in base a come si immagini che i dati vengano acceduti dal mondo esterno. In DynamoDB ogni riga deve essere univoca e questo avviene tramite la Primary Key: questa può essere formata solo dalla Partition Key o dall’insieme di Partition Key e Sort Key.
Note
Ci sono solo due modi per interrogare una tabella DynamoDB: fornendo la PK o una combinazione tra PK e SK.
Ogni tabella quindi deve avere una colonna PK obbligatoria e una colonna SK opzionale.
- Partition Key (PK):
- È l’identificatore unico di un elemento in una tabella.
- Ogni valore di PK deve essere unico in tutta la tabella.
- Quando usi solo la PK, stai creando una “chiave primaria semplice”.
- E’ chiamato partition key in quanto viene identificato per trovare la partizione del “cluster” dove si trova l’oggetto in questione.
- Sort Key (SK):
- È opzionale e viene utilizzata insieme alla PK per formare una chiave primaria “composta”.
- La PK e la SK insieme devono essere univoche.
- La SK permette di avere più elementi con la stessa PK, ma differenziati dalla SK.
- Si chiama così perché a parità di PK, gli elementi vengono ordinati secondo una SK.
La scelta tra usare solo una Partition Key (PK) o una combinazione di PK e Sort Key (SK) dipende dal tipo di dati che vuoi memorizzare e da come li vuoi interrogare: usa solo la PK quando ogni elemento è indipendente e non ci sono relazioni o necessità di ordinamento. Usa PK e SK quando devi organizzare dati correlati, mantenere un ordine logico o effettuare query più specifiche.
Nota
In DynamoDB le pk e sk possono essere binary, string o number. Tipicamente la scelta migliore è sempre string. Inoltre come nome colonna è buona cosa chiamarle proprio
pkesk.
La PK è il principale identificatore unico per ogni elemento nella tabella. Ogni valore di PK deve essere unico, quindi è perfetto quando ogni elemento rappresenta un’entità indipendente.
Ad esempio, se stai creando una tabella per memorizzare gli utenti di un sistema, la PK potrebbe essere il loro UserID. Ogni utente ha un ID unico, quindi puoi facilmente usare solo la PK per identificarli e memorizzare informazioni come nome, email e indirizzo.
Quando invece hai bisogno di raggruppare dati correlati o di mantenere un ordine specifico, entra in gioco la SK. In questo caso è univoca l’unione tra PK e SK.
Quando richiedo i dati fornendo una PK, tutte le righe con tale PK verranno automaticamente ordinate secondo la SK, ed è per quello che si chiama sort key.
Un esempio classico di utilizzo di SK è come colonna data, in modo che automaticamente i valori vengano ordinati dal più vecchio al più giovane o viceversa.
Come funziona la Partition Key
Possiamo immaginare DynamoDB come un cluster: ogni tabella ad alto livello lato utilizzatore è solo una tabella ma internamente è un cluster di vari nodi sparsi.
Ogni nodo del cluster ha al suo interno un range di hash di partition key che gestisce: per esempio il nodo 1 ha al suo interno tutte le PK il cui valore inizia con 0fAf, il nodo 2 tutti gli hash che iniziano con 0b5d e così via.
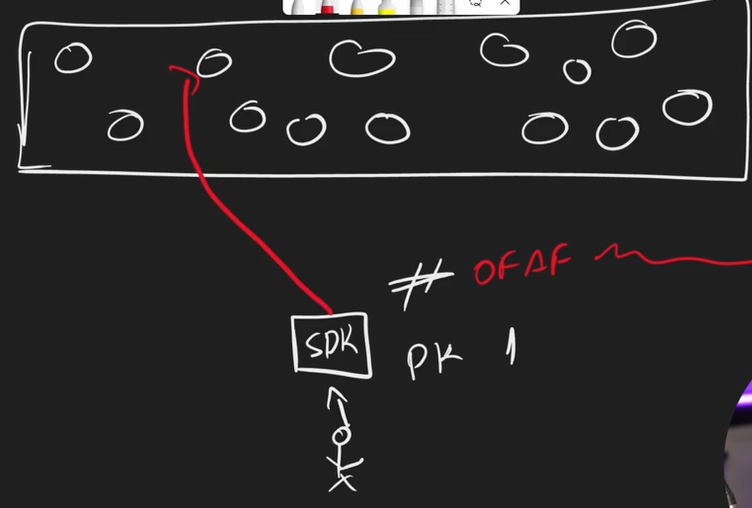 In questo modo quando richiedo un oggetto fornendo la PK viene fatto l’hash di questa ultima e riesco subito a capire a quale nodo andare a recuperare l’informazione senza provarli tutti: questo permette al db di essere estremamente veloce anche con TB di dati.
Ogni nodo del cluster può contenere massimo 10GB di dati; in questo modo sono sicuro che nel caso peggiore dovrò cercare un elemento in un db di massimo 10GB anche se il mio db contiene 1000TB di dati.
In questo modo quando richiedo un oggetto fornendo la PK viene fatto l’hash di questa ultima e riesco subito a capire a quale nodo andare a recuperare l’informazione senza provarli tutti: questo permette al db di essere estremamente veloce anche con TB di dati.
Ogni nodo del cluster può contenere massimo 10GB di dati; in questo modo sono sicuro che nel caso peggiore dovrò cercare un elemento in un db di massimo 10GB anche se il mio db contiene 1000TB di dati.
Pk e performance
Affinché il mio database sia performante come vorrei ad ogni operazione che faccio devo fornire la PK. Quando scelgo la PK devo farlo sapendo che tale valore dovrà sempre essere fornito, in ogni query (per quello DynamoDB si usa solo quando gli access patterns sono noti). Se non fornisco la PK dovrà essere fatta l’operazione di scanning o cross partition query che significa andare in tutti i nodi a cercare se contengono il dato che sto cercando: questa operazione è lunga e costosa e bisognerebbe evitarla a tutti i costi.
Secondary indexes
Dato che posso effettuare una query solo fornendo PK e SK come faccio a filtrare basandomi su altri campi che non siano questi due? Queste feature non sono necessarie se si effettua un buon table design all’inizio in quanto servono per poter gestire use case e access pattern che non erano state pensate all’inizio della progettazione; questo ad un costo non trascurabile.
Global Secondary Indexes (GSI)
Assumiamo di avere una tabella per i film in cui la pk è il nome del film e la sk è l’anno di uscita.
Assumiamo ora di dover rispondere alla query “fornisci tutti i film usciti nel 2017”: questa query non è possibile in quanto non posso fornire nella query la pk in quanto è il nome del film. L’unico modo sarebbe fare lo scanning di tutti i record e eseguire il filtraggio in locale, cosa lentissima e costosissima.
Un’alternativa è usare un GSI che di fatto duplica la tabella in un’altra con un’altra pk diversa sincronizzando le due. Questo significa che ogni volta che salvo qualcosa devo replicarla per tutti gli indici, come anche lo spazio raddoppia e così via.
Questa feature è quindi da utilizzare come ultima spiaggia.
Local Secondary Indexes (LSI)
E’ un modo per aumentare gli access patterns alla tabella, in particolare lavora come se la tabella avesse più sk.
- Questo indice può essere creato solo contestualmente alla creazione della tabella e non può essere creato retroattivamente.
- Può essere usato solo su una tabella che ha primary key composta sia da
pkche dask - Non può essere eliminato ma nasce e muore insieme alla tabella
- Quando faccio una query ad un LSI posso richiedere se eventual consistency o strong consistency
Esempio
In questo esempio utilizzo l’IndexName per accedere all’indice (che sia GSI o LSI è indifferente) chiamato year-rotten-index.
var queryRequest = new QueryRequest
{
TableName = "movies",
IndexName = "year-rotten-index",
KeyConditionExpression = "ReleaseYear = :v_Year and RottenTomatoesPercentage >= :v_Rotten",
ExpressionAttributeValues = new Dictionary<string, AttributeValue>
{ { ":v_Year", new AttributeValue { N = "2018" } },
{ ":v_Rotten", new AttributeValue { N = "88" } }
}};Streams
L’obiettivo è poter generare un evento ogni volta che accade qualcosa sul database: questo evento può essere ascoltato da una Lambda che poi gestisce quello che c’è da fare. In questo modo non ho nemmeno bisogno di SNS per essere notificato ma posso ascoltare direttamente il database. Ogni evento è un record che contiene il nome della tabella, dei metadata, un timestamp e alcune informazioni che dipendono dai dati specifici.
Come abilitarli
tabella -> Export and streams -> DynamoDB stream details -> Turn on.
Qui ci sono quattro opzioni che permettono di indicare cosa voglio fornire al listener quando viene modificato un eelemento:
- Key attributes only: fornisce solo
pkosk - New image: fornisce il nuovo oggetto
- Old image: fornisce il vecchio oggetto prima della modifica (inutile)
- New and old image: la combinazione dei due sopra.
Pricing
Il prezzo di DynamoDB funziona con un sistema a crediti che, oltre allo storage effettivo, si basa su due valori principali:
- Read Capacity Units (RCU): riguardano la lettura, quindi la lettura di un valore puntuale (economica) o lo scanning (costosa)
- Write Capacity Units (WCU): riguardano l’aggiornamento di un valore esistente o la sua eliminazione
L’interfaccia per analizzare e modificare è
Read/write capacitye si divide in: - On-demand: gestisce qualsiasi numero di richieste per secondo ma è più costoso. Ha senso solo in caso di applicazioni con picchi di traffico non prevedibili.
- Provisioned: viene deciso il minimo e massimo RCU e WCU con eventualmente l’auto scale in caso di richieste maggiori.
Auto scaling
Invece di pagare RCU e WCU fisse posso impostare l’auto-scale in modo che il sistema aggiorni automaticamente le RCU e WCU che sto pagando fino ad un valore massimo/minimo.
Tricks
Questi suggerimenti valgono ovviamente per enormi moli di dati.
- Riduci la lunghezza dei nomi degli attributi in modo da occupare meno spazio
- Non salvare mai un file in DynamoDB o stringhe base64. Si usa S3 per quello.
- Mai effettuare scans
- Usa Eventually Consistent reads il più possibile
- Una buona modellazione degli access pattern evita di usare LSI e GSI che sono costosi
- Non usare on-demand capacity ma sfrutto l’auto scaling
Letture
Tipologie
| Tipo di Lettura | Consistenza | Latenza | Costo (per KB) | Utilizzo Tipico |
|---|---|---|---|---|
| Strongly Consistent | Alta | Maggiore | 1 RCU | Sistemi sensibili alla consistenza |
| Eventually Consistent | Bassa (si sincronizza nel tempo) | Bassa | 0.5 RCU | Applicazioni con tolleranza al ritardo |
| Transactional Reads | Alta + ACID | Maggiore | 2 RCU | Transazioni critiche e operazioni complesse |
| Il livello di consistenza viene passato come parametro quando leggo. Di default DynamoDB utilizza le eventually consistent. |
Strongly Consistent Reads
Una lettura fortemente consistente garantisce che quando recuperi i dati, stai leggendo l’ultima versione aggiornata di quell’elemento. In pratica, DynamoDB verifica che la lettura rifletta tutte le scritture completate con successo fino a quel momento.
- Pro:
- Consistenza assoluta: ottieni sempre i dati più aggiornati.
- Ideale per applicazioni che richiedono garanzie forti (es. sistemi finanziari).
- Contro:
- Maggiore latenza rispetto a una lettura eventualmente consistente;
- Non supportata sui GSIs;
- Potrebbe non essere disponibile, in quel caso 500;
- Consuma molto di più in termini di capacità del server.
- Costo:
- Ogni lettura fortemente consistente costa 1 unità di lettura per KB di dati fino a 4KB di dati.
Eventually Consistent Reads
Una lettura eventualmente consistente non garantisce che tu stia leggendo l’ultima versione dei dati. Potresti ottenere dati obsoleti se ci sono aggiornamenti recenti. Tuttavia, DynamoDB assicura che i dati si sincronizzino nel tempo (in genere entro un secondo).
- Pro:
- Latenza più bassa rispetto alla lettura fortemente consistente.
- Maggiore throughput: costa metà delle unità di lettura di una lettura fortemente consistente.
- Contro:
- I dati potrebbero non essere aggiornati.
- Non adatto a sistemi critici o che richiedono coerenza immediata.
- Costo:
- Ogni lettura eventualmente consistente costa 0.5 unità di lettura per KB di dati fino a 4KB di dati
Transactional Reads
Una lettura transazionale fa parte di una transazione che garantisce consistenza assoluta su più elementi. Può essere utilizzata per garantire ACID (Atomicità, Consistenza, Isolamento, Durabilità) per operazioni su tabelle o indici secondari globali.
- Pro:
- Perfetta per applicazioni critiche che richiedono operazioni atomiche su più elementi.
- Assicura consistenza fortemente consistente in un contesto transazionale.
- Contro:
- Maggiore latenza rispetto a letture standard.
- Più costosa.
- Costo:
- Ogni lettura transazionale costa 2 unità di lettura per KB di dati fino a 4KB di dati, dato che offre sia consistenza forte sia garanzie transazionali.
.NET
Utilizza la classe AmazonDynamoDBClient per inviare richieste dirette a DynamoDB, i metodi principali sono:
PutItemAsync: Inserisce un nuovo elemento nella tabella.GetItemAsync: Recupera un elemento specifico.UpdateItemAsync: Aggiorna un elemento esistente.DeleteItemAsync: Rimuove un elemento.QueryAsync: Recupera elementi basandosi su unapk.ScanAsync: Recupera tutti gli elementi della tabella (potenzialmente inefficiente).
Put
Per prima cosa devo averte un oggetto Dto che rappresenta una riga della tabella su DynamoDB; come si vede ci sono le property pk e sk con l’attributo JsonPropertyName.
public class CustomerDto
{
[JsonPropertyName("pk")]
public string Pk => Id.ToString();
[JsonPropertyName("sk")]
public string Sk => Id.ToString();
public Guid Id { get; init; } = default!;
public string FullName { get; init; } = default!;
public string Email { get; init; } = default!;
}Poi per usare il metodo PutItemAsync devo convertirlo in Json e ottenerne l’attributeMap come si vede sotto.
public async Task<bool> CreateAsync(CustomerDto customer)
{
customer.UpdatedAt = DateTime.UtcNow;
var customerAsJson = JsonSerializer.Serialize(customer);
var customerAsAttributes = Document.FromJson(customerAsJson).ToAttributeMap();
var createItemRequest = new PutItemRequest
{
TableName = _tableName,
Item = customerAsAttributes,
ConditionExpression = "attribute_not_exists(pk) and attribute_not_exists(sk)"
};
var response = await _dynamoDb.PutItemAsync(createItemRequest);
return response.HttpStatusCode == HttpStatusCode.OK;
}Get
Per ottenere un valore devo obbligatoriamente fornire il pk e eventualmente l’sk, vedi l’esempio sotto.
public async Task<CustomerDto?> GetAsync(Guid id)
{
var getItemRequest = new GetItemRequest
{
TableName = _tableName,
Key = new Dictionary<string, AttributeValue>
{
{ "pk", new AttributeValue { S = id.ToString() } },
{ "sk", new AttributeValue { S = id.ToString() } }
}
};
var response = await _dynamoDb.GetItemAsync(getItemRequest);
if (response.Item.Count == 0)
{
return null;
}
var itemAsDocument = Document.FromAttributeMap(response.Item);
return JsonSerializer.Deserialize<CustomerDto>(itemAsDocument.ToJson());
}Scanning
Warning
Questa operazione è estremamente lenta e costosa, non andrebbe mai fatta. Se viene fatta troppo spesso significa che ci sono dei problemi architetturali che bisognerebbe risolvere a monte.
var scanRequest = new ScanRequest
{
TableName = _tableName
};
var response = await _dynamoDb.ScanAsync(scanRequest);
return response.Items.Select(x =>
{
var json = Document.FromAttributeMap(x).ToJson();
return JsonSerializer.Deserialize<CustomerDto>(json);
})!;Update
Può accadere che io voglia aggiornare un valore che qualcun altro ha già aggiornato nel frattempo: la mia modifica andrebbe ad invalidare la sua che non è cosa che voglio.
Per risolvere posso utilizzare il campo UpdatedAt dell’oggetto su db insieme alla ConditionExpression che verifica che il suo valore sia inferiore a quando è iniziata la richiesta, che è la variabile requestStarted.
public async Task<bool> UpdateAsync(CustomerDto customer, DateTime requestStarted)
{
customer.UpdatedAt = DateTime.UtcNow;
var customerAsJson = JsonSerializer.Serialize(customer);
var customerAsAttributes = Document.FromJson(customerAsJson).ToAttributeMap();
var updateItemRequest = new PutItemRequest
{
TableName = _tableName,
Item = customerAsAttributes,
ConditionExpression = "UpdatedAt < :requestStarted",
ExpressionAttributeValues = new Dictionary<string, AttributeValue>
{ { ":requestStarted", new AttributeValue{S = requestStarted.ToString("O")} }
} };
var response = await _dynamoDb.PutItemAsync(updateItemRequest);
return response.HttpStatusCode == HttpStatusCode.OK;
}