Train set (train_X) - Set di addestramento
Il train set è l’insieme di dati utilizzato per addestrare un modello di machine learning. Questi dati vengono utilizzati per insegnare al modello come fare previsioni basate sulle feature fornite. Il modello cerca di apprendere relazioni e pattern nei dati di addestramento in modo da poter fare previsioni accurate sui dati futuri.
Validation set (val_X) - Set di convalida
Questo set di dati è utilizzato per testare diverse configurazioni del modello e per ottimizzare i suoi Iperparametri. Ad esempio, se stiamo costruendo un modello di rete neurale, possiamo utilizzare il validation set per regolare il numero di strati nascosti o il tasso di apprendimento al fine di migliorare le prestazioni del modello.
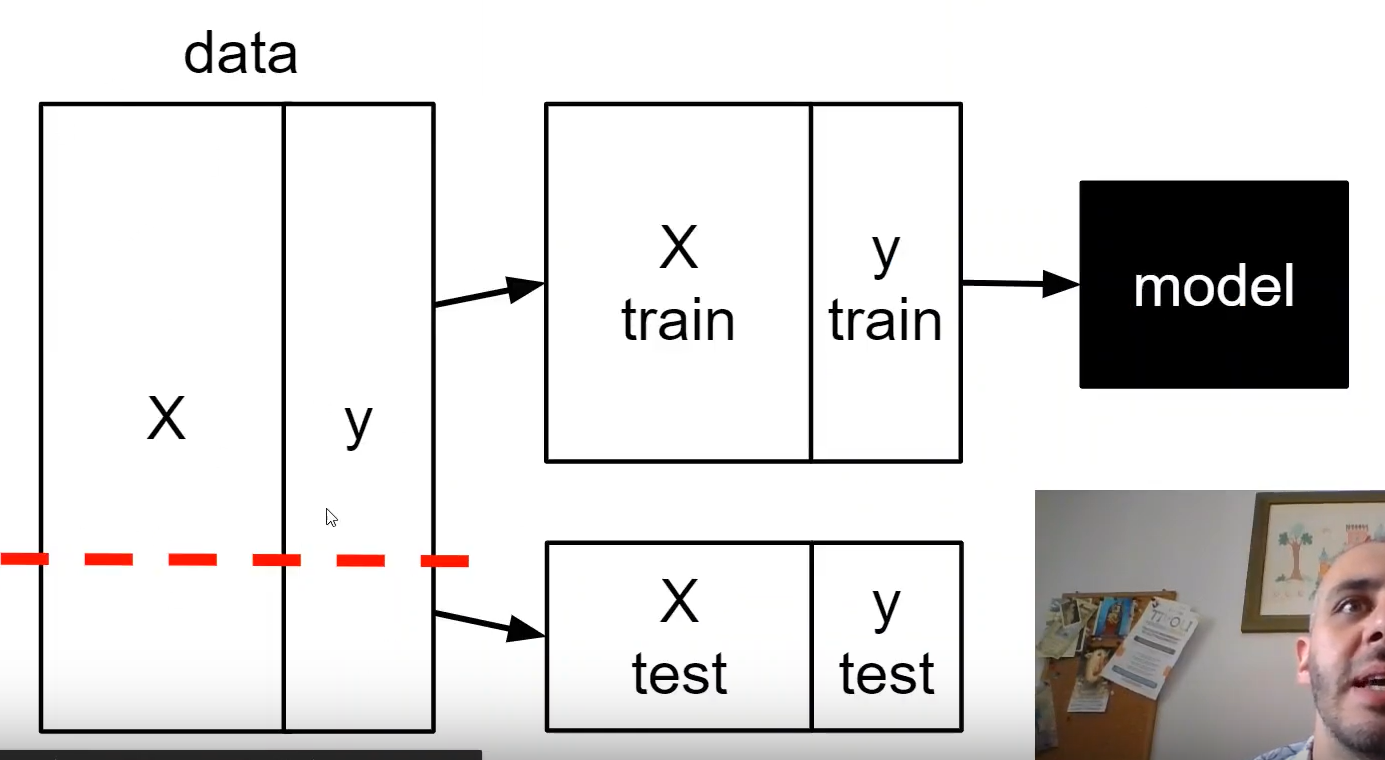
Test set (test_X) - Set di test
Viene utilizzato per valutare le prestazioni del modello e misurare la sua capacità di fare previsioni su dati non visti in precedenza. Il test set serve a valutare se il modello è in grado di generalizzare correttamente dalle informazioni apprese durante l’addestramento.
Se dobbiamo dividere un dataset nei tre dataset, dobbiamo tenere in considerazione che stiamo sottraendo informazioni preziose, di cui l’algoritmo di apprendimento potrebbe fare buon uso. Pertanto, non vogliamo allocare troppe informazioni nel set di test. Tuttavia, più piccolo è il set di test, più sarà imprecisa la stima dell’errore di generalizzazione.
Le divisioni più comunemente utilizzate sono 60:40, 70:30 o 80:20 a seconda delle dimensioni del dataset iniziale. Tuttavia, per grossi dataset, possono essere comuni e appropriate anche suddivisioni del tipo 90:10 o 99:1.
Per vederne un esempio vedi la funzione train_test_split di Scikit Learn.
train_test_split
Input:
X: Un dataframe contenente le features del dataset.y: Un array contenente le etichette del dataset.test_size: La proporzione di dati da assegnare al set di test. Ad esempio, setest_sizeè impostato su 0.2, il 20% dei dati sarà nel set di test.random_state: Un seme casuale per garantire la riproducibilità dei risultati.- Altri parametri opzionali per controllare la suddivisione, come
shuffleestratify.
Output:
X_train: Il set di addestramento contenente le caratteristiche.X_test: Il set di test contenente le caratteristiche.y_train: Il set di addestramento contenente le etichette.y_test: Il set di test contenente le etichette.
Funzionamento:
- I dati iniziali sono suddivisi in due gruppi: il set di addestramento e il set di test. La dimensione di ciascun set è determinata dalla proporzione specificata con
test_size. - Se
shuffleè impostato suTrue, i dati sono mischiati casualmente prima della suddivisione. Questo è utile per garantire che i dati siano distribuiti in modo casuale nei set di addestramento e test. - Se il parametro
stratifyè impostato, la suddivisione viene effettuata in modo da mantenere la stessa distribuzione delle classi tra il set di addestramento e il set di test. Questo è utile in problemi di classificazione per evitare che uno dei set contenga una percentuale sbilanciata di campioni da diverse classi. - I dati suddivisi vengono restituiti sotto forma di quattro array o dataframe:
X_train,X_test,y_train, ey_test, che rappresentano il set di addestramento e il set di test delle caratteristiche e delle etichette, rispettivamente.
Ecco un esempio di utilizzo di train_test_split in Python:
from sklearn.model_selection import train_test_split
X = ... # Caratteristiche del dataset
y = ... # Etichette del dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Una volta completata la suddivisione, è possibile utilizzare X_train e y_train per addestrare il modello e X_test e y_test per valutarne le prestazioni.