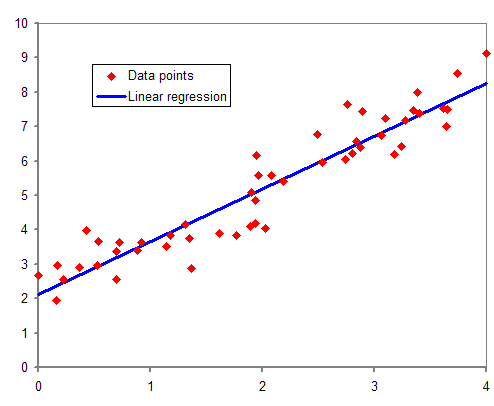
La regressione lineare è una tecnica di machine learning che ci aiuta a capire come una variabile dipendente (Y) è influenzata da una o più variabili indipendenti (X).
Data una variabile predittiva x e una variabile risposta y, tracciamo una linea retta attraverso questi dati in modo da minimizzare la distanza (si parla infatti di distanza quadratica media) fra i punti del campione e la linea.
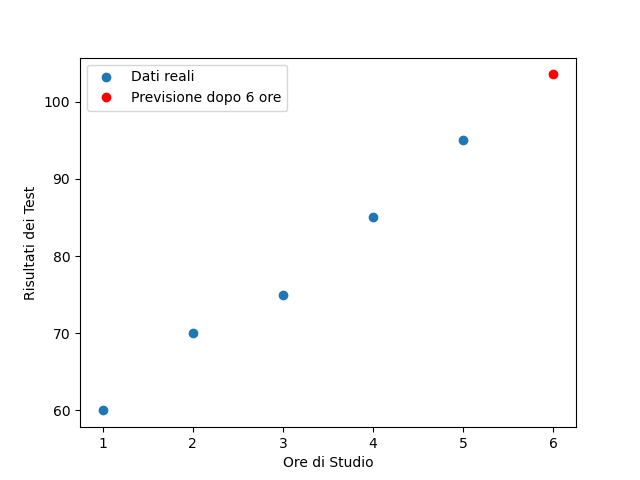
Immagina di avere dati che mostrano il numero di ore studiate (X) e i risultati dei test (Y) di alcuni studenti.
La regressione lineare può aiutarci a stabilire quanto il tempo di studio influenzi i risultati dei test. Se tracciamo una linea retta attraverso questi punti, otteniamo una stima approssimativa di come i risultati dei test cambino al variare delle ore di
studio.
Definizione matematica
Ecco la formula matematica in LaTeX per la regressione lineare semplice:
Y=β0+β1X+ε
Nella formula:
Y rappresenta la variabile dipendente.
X rappresenta la variabile indipendente.
β0 è l’intercetta (il valore previsto di Y quando X=0.
β1 è il coefficiente di regressione associato a X (peso).
ε rappresenta l’errore residuo, che è la differenza tra i valori previsti da questo modello e i valori osservati (bias).
Esempio con Keras
Ecco un semplice esempio in Python per calcolare una regressione lineare: abbiamo addestrato un modello di regressione lineare per prevedere i risultati del test in base alle ore di studio.
Nel nostro caso, stiamo creando una rete neurale con un singolo neurone, che è essenzialmente una regressione lineare. La rete sarà addestrata a modificare i pesi (il coefficiente e l’intercetta della retta) in modo che la retta si adatti ai dati nel modo migliore possibile.
La rete dovrà trovare il peso e il bias in modo da minimizzare l’errrore.
Il modello ci permette di fare previsioni per nuovi dati, ad esempio, prevedendo che dopo 6 ore di studio, il risultato del test sarà vicino a 105.
import numpy as npimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersimport matplotlib.pyplot as plt# Dati di esempio: ore di studio e risultati dei test ore_di_studio = np.array([1, 2, 3, 4, 5]) risultati_test = np.array([60, 70, 75, 85, 95]) # Creiamo un modello di regressione lineare con un singolo neurone # Sequential in quanto gli strati di neuroni vengono aggiunti uno dopo l'altro # layers.Dense indice che lo strato è denso (fully connected) # units=1 lo strato ha un solo neurone # input_shape=[1]: il neurone ha un'unico input modello = keras.Sequential([ layers.Dense(units=1, input_shape=[1]) ]) # Compiliamo il modello specificando l'ottimizzatore e la funzione di costo # Ottimizzazione sgd indica la modalità "discesa del gradiente stocastica" # la funzione di costo è lo scarto quadratico medio modello.compile(optimizer='sgd', loss='mean_squared_error') # Addestriamo il modello con i dati per 1000 epoche. modello.fit(ore_di_studio, risultati_test, epochs=1000, verbose=0) # Ora possiamo fare previsioni previsione = modello.predict(np.array([6])) print("Previsto risultato del test dopo 6 ore di studio:", previsione[0, 0])# Visualizza i dati reali e le previsioni plt.scatter(ore_di_studio, risultati_test, label='Dati reali') plt.plot(6, previsione[0, 0], 'ro', label='Previsione dopo 6 ore') plt.xlabel('Ore di Studio') plt.ylabel('Risultati dei Test') plt.legend() plt.show()
In questo esempio, abbiamo utilizzato Keras per creare un modello di regressione lineare con un singolo neurone. Abbiamo compilato il modello specificando l’ottimizzatore “sgd” (discesa del gradiente stocastica) e Loss function “mean_squared_error”. Quindi abbiamo addestrato il modello per 1000 epoche con i dati di studio e risultati dei test.
keras.Sequential
La riga di codice modello = keras.Sequential([layers.Dense(units=1, input_shape=[1])]) è fondamentale, andiamo a spiegare ogni parte della riga:
Sequential: keras.Sequential è un tipo di modello di rete neurale. In un modello sequenziale, gli strati sono disposti uno dopo l’altro in una sequenza lineare. Ciò significa che i dati in ingresso passano attraverso ogni strato nell’ordine in cui sono stati aggiunti.
layers.Dense(units=1, input_shape=[1]): Questo è lo strato che definisce il nostro modello. Vediamo cosa significa ciascun argomento:
layers: Questo fa riferimento al modulo layers all’interno di Keras, che contiene le definizioni degli strati della rete neurale.
Dense: Questo è uno strato completamente connesso, anche noto come strato denso o fully connected layer. In uno strato denso, ogni neurone è connesso a tutti i neuroni dello strato precedente e successivo. Nell’ambito della regressione lineare, uno strato denso è esattamente ciò di cui abbiamo bisogno perché vogliamo che ogni input sia collegato direttamente al neurone di output.
units=1: L’argomento units specifica il numero di neuroni nello strato. In questo caso, stiamo usando un solo neurone. Poiché la regressione lineare cerca di trovare una relazione lineare, un singolo neurone è sufficiente per modellare questa relazione. Il neurone di output rappresenterà la stima prevista dei risultati dei test in base alle ore di studio.
input_shape=[1]: Questo argomento specifica la forma dell’input che il modello può accettare. Nel nostro caso, abbiamo un solo input (le ore di studio), quindi input_shape è [1]. Questa è la dimensione dell’input, cioè il numero di variabili indipendenti nel nostro problema.
Ora, una volta che abbiamo capito cosa fa questa riga, vediamo alcune alternative o variazioni che potrebbero essere utilizzate:
Più strati Dense: Se il tuo problema è più complesso, potresti voler aggiungere più strati densi prima di ottenere il risultato finale. Questo potrebbe rendere il modello più adatto a relazioni non lineari nei dati.
modello = keras.Sequential([ layers.Dense(units=64, activation='relu', input_shape=[1]), layers.Dense(units=1)])
Qui, abbiamo aggiunto un secondo strato denso con 64 neuroni e una funzione di attivazione “relu”. Questo può essere utile per problemi più complessi.
Funzione di attivazione: Nell’esempio precedente, ho menzionato la “funzione di attivazione”. In un modello di regressione lineare, la funzione di attivazione può essere lineare (che è l’opzione predefinita). Tuttavia, per problemi più complessi, potresti voler utilizzare funzioni di attivazione non lineari come “relu” o “sigmoid” per catturare relazioni più intricate nei dati.
modello = keras.Sequential([ layers.Dense(units=1, activation='relu', input_shape=[1])])
Altre architetture di modelli: Keras consente la creazione di modelli più complessi con architetture diverse, ad esempio reti neurali profonde o reti neurali ricorrenti. Queste architetture possono essere utilizzate in casi in cui la regressione lineare standard non è sufficiente per modellare i dati.
modello = keras.Sequential([ layers.Dense(units=64, activation='relu', input_shape=[1]), layers.Dense(units=32, activation='relu'), layers.Dense(units=1)])
Variabili multiple: Nel nostro esempio, abbiamo un solo input (ore di studio), ma la regressione lineare può gestire più variabili indipendenti. In tal caso, dovresti impostare input_shape in base al numero di variabili.
modello = keras.Sequential([ layers.Dense(units=1, input_shape=[2])])
Qui abbiamo due variabili indipendenti e input_shape è impostato su [2].
model.Compile
Per comprendere la riga modello.compile(optimizer='sgd', loss='mean_squared_error') dobbiamo suddividerla in tre parti principali: compile, optimizer, e loss. Vediamo cosa fa ciascuna di queste parti.
compile: Il metodo compile è utilizzato per configurare il processo di addestramento del modello. Durante questa fase, specifichiamo le impostazioni chiave che definiscono come il modello apprenderà dai dati e come misurerà la sua performance. È un passaggio essenziale prima di iniziare l’addestramento.
optimizer='sgd': L’argomento optimizer definisce l’ottimizzatore che il modello utilizzerà per regolare i pesi durante l’addestramento. In questo caso, 'sgd' sta per “Stochastic Gradient Descent” (Discesa del Gradiente Stocastica), che è uno degli ottimizzatori più comuni utilizzati nel machine learning. La discesa del gradiente è un algoritmo di ottimizzazione che cerca di trovare i pesi del modello che minimizzano una funzione di costo. Ciò significa che il modello si “sposta” nella direzione in cui la funzione di costo è in diminuzione, cercando di avvicinarsi al minimo globale. Questa funzione di costo è una misura di quanto bene il modello si adatta ai dati durante l’addestramento. L’uso di un ottimizzatore come la discesa del gradiente è fondamentale perché permette al modello di migliorare gradualmente la sua capacità di fare previsioni accurate.
Alternative all’ottimizzatore: Esistono diverse alternative all’ottimizzatore SGD, ognuna con le proprie caratteristiche e vantaggi. Alcuni degli ottimizzatori più comuni includono “Adam”, “RMSprop”, e “Adagrad”. Ogni ottimizzatore ha il suo comportamento specifico e può essere più efficace in determinate situazioni. La scelta dell’ottimizzatore dipenderà dal problema e dall’architettura del modello.
# Esempio con ottimizzatore diverso (Adam)modello.compile(optimizer='adam', loss='mean_squared_error')
loss='mean_squared_error': L’argomento loss definisce la funzione di costo che il modello utilizzerà per valutare quanto bene si adatta ai dati durante l’addestramento. In questo caso, 'mean_squared_error' (errore quadratico medio) è una comune funzione di costo per problemi di regressione. L’MSE calcola la discrepanza tra le previsioni del modello e i dati effettivi, elevando questa discrepanza al quadrato e calcolandone la media. L’errore quadratico medio misura la discrepanza tra le previsioni del modello e i valori reali dei dati. L’obiettivo dell’addestramento è minimizzare questa discrepanza.
Alternative alla funzione di costo: A seconda del tipo di problema, è possibile utilizzare diverse funzioni di costo. Ad esempio, per la classificazione binaria, è comune utilizzare "binary_crossentropy", mentre per la classificazione multiclasse, si utilizza spesso "categorical_crossentropy". La scelta della funzione di costo è cruciale e dipende dal tipo di problema che si sta risolvendo.
# Esempio con un'altra funzione di costo (entropia incrociata categorica)modello.compile(optimizer='sgd', loss='categorical_crossentropy')
model.fit
La riga di codice modello.fit(ore_di_studio, risultati_test, epochs=1000, verbose=0) è fondamentale, per comprendere appieno questa riga, dobbiamo suddividerla in quattro parti principali: fit, ore_di_studio, risultati_test, e i parametri epochs e verbose. Vediamo cosa fa ciascuna di queste parti.
fit: Il metodo fit è utilizzato per addestrare il modello con i dati forniti. Questa è la fase in cui il modello impara dalle osservazioni fornite nel dataset. Durante il processo di addestramento, il modello regola i suoi pesi in modo da minimizzare una funzione di costo specificata, migliorando così la sua capacità di fare previsioni accurate.
ore_di_studio: Questo parametro rappresenta i dati di input, in questo caso, le ore di studio. Questi dati costituiscono la variabile indipendente che il modello utilizzerà per fare previsioni. In sostanza, ore_di_studio è l’insieme dei dati che il modello utilizzerà per imparare la relazione tra le ore di studio e i risultati dei test.
risultati_test: Questo parametro rappresenta i dati di output o le etichette, in questo caso, i risultati dei test. Questi dati costituiscono la variabile dipendente che il modello cercherà di prevedere. Il modello utilizzerà risultati_test per valutare quanto bene le sue previsioni si avvicinano ai valori reali.
epochs=1000: L’argomento epochs specifica il numero di Epoche di addestramento. Un’epoca rappresenta una singola iterazione attraverso l’intero dataset di addestramento. Durante ciascuna epoca, il modello utilizza tutti i dati di addestramento per aggiornare i suoi pesi. Il numero di epoche è un iperparametro che definisce quanto a lungo il modello viene addestrato. Un numero maggiore di epoche può consentire al modello di apprendere meglio dai dati, ma può anche comportare un addestramento più lungo.
Alternative per il numero di epoche: Il numero di epoche è un parametro che può variare a seconda del problema. È possibile eseguire l’addestramento per un numero fisso di epoche, oppure è possibile utilizzare tecniche come l’early stopping, che interrompono l’addestramento quando il modello smette di migliorare.
# Esempio con early stoppingfrom tensorflow.keras.callbacks import EarlyStoppingearly_stopping = EarlyStopping(monitor='val_loss', patience=10)modello.fit(ore_di_studio, risultati_test, epochs=1000, callbacks=[early_stopping])
verbose=0: L’argomento verbose controlla la quantità di informazioni di progresso che vengono visualizzate durante l’addestramento. Se verbose è impostato su 0, nessuna informazione di progresso verrà visualizzata durante l’addestramento. Questo può essere utile se si desidera eseguire l’addestramento in modalità silenziosa. Altri valori comuni per verbose includono 1 e 2, che forniscono informazioni di progresso crescenti durante l’addestramento.
Alternative per il livello di verbosità: Se si desidera monitorare il progresso dell’addestramento, è possibile impostare verbose su 1 o 2. Questo fornirà informazioni sull’andamento dell’addestramento, come l’epoca corrente e la funzione di costo. La scelta del livello di verbosità dipende dalle preferenze dell’utente e dalla necessità di monitorare il progresso.
# Esempio con verbose=1 (informazioni di progresso durante l'addestramento)modello.fit(ore_di_studio, risultati_test, epochs=1000, verbose=1)
model.predict
La riga di codice modello.predict(np.array([6])) specifica l’input da dare al modello e chiede al modello di generare una previsione basata su quell’input.
modello.predict: Questo è il metodo utilizzato per generare previsioni con un modello già addestrato.
np.array([6]): Questo è l’input fornito al modello per generare la previsione. Nell’esempio dato, stiamo fornendo un singolo valore, cioè 6.
Alternative all’input: L’input fornito al modello può variare notevolmente a seconda del tipo di modello e del problema che si sta risolvendo. Ad esempio, se il modello è stato addestrato per l’elaborazione del linguaggio naturale, l’input potrebbe essere una sequenza di parole o frasi. Se si tratta di un modello di immagine, l’input potrebbe essere un’immagine rappresentata come un array di pixel.
# Esempio di input diverso (array NumPy con più valori)input_data = np.array([3, 5, 8, 10])modello.predict(input_data)
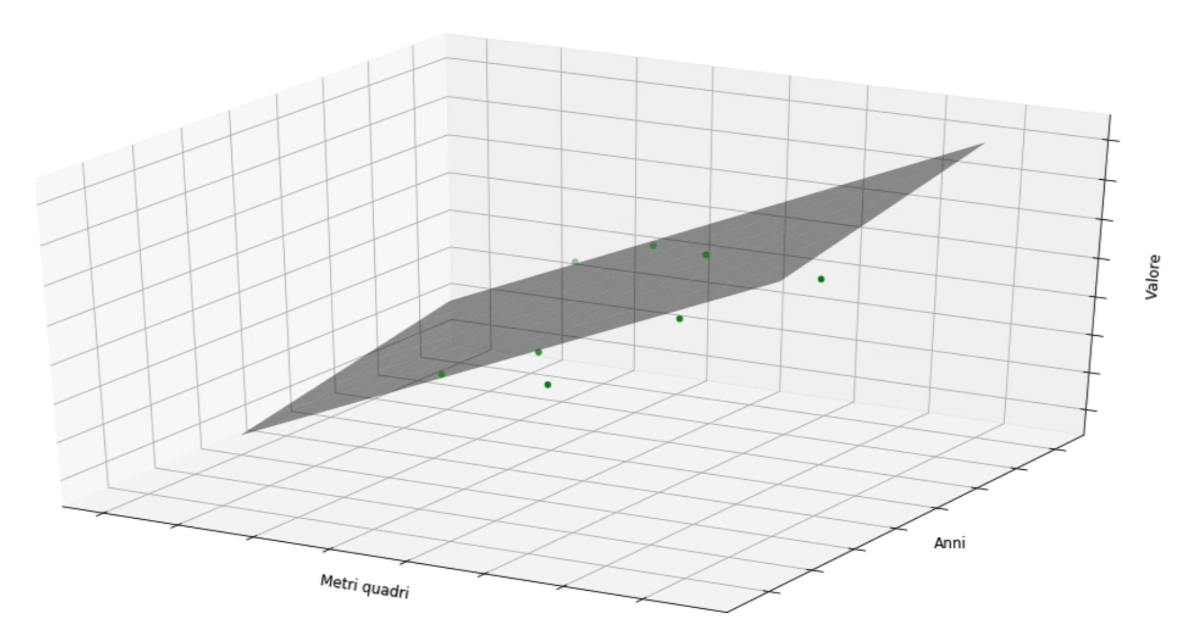
Regressione lineare multipla
La regressione lineare multipla è un metodo statistico utilizzato nell’analisi dei dati per modellare la relazione tra una variabile dipendente (o target) e due o più variabili indipendenti (o predittori) attraverso un modello lineare.
Questo modello è espresso mediante un’equazione lineare che cerca di spiegare la variazione nella variabile dipendente in termini delle variabili indipendenti. In altre parole, cerca di trovare una relazione lineare che migliori si adatti ai dati osservati.
L’equazione della regressione lineare multipla può essere espressa come segue:
Y=β0+β1X1+β2X2+...+βnXn+ε
Dove:
Y rappresenta la variabile dipendente.
X1,X2,...,Xn rappresentano le variabili indipendenti.
β0 rappresenta l’intercetta (il valore previsto di Y quando tutte le variabili indipendenti sono uguali a zero).
β1,β2,...,βn rappresentano i coefficienti di regressione (pesi) associati alle variabili indipendenti.
ε rappresenta l’errore residuo, ovvero la differenza tra i valori previsti dal modello e i valori osservati (bias).
La regressione lineare multipla si distingue dalla semplice regressione lineare nel senso che la semplice regressione coinvolge solo una variabile indipendente e una variabile dipendente, mentre la regressione lineare multipla coinvolge più variabili indipendenti.