Introduzione
Gli algoritmi di edge detection sono algoritmi che assegnano un valore ad ogni pixel in proporzione del fatto che quel pixel faccia parte di un “bordo” in un’immagine o meno. Per bordo di intende un’area di confine tra due zone di pixel di diversa intensità. Il più noto algoritmo di edge detection è Canny: questo prende in ingresso un’immagine in scala di grigi e produce in uscita un’immagine che enfatizza la posizione dei bordi.
Funzionamento
L’algoritmo funziona tramite più elaborazioni distinte dell’immagine in ingresso. Prima di tutto l’immagine viene sfocata tramite la convoluzione con un kernel gaussiano, poi viene applicato un operatore derivativo per enfatizzare maggiormente le regioni con derivata molto alta (quindi dove ho un brusco cambiamento nell’intensità dei pixel). I bordi dell’immagine creano quindi delle creste nell’immagine derivata sopra. Ora l’algoritmo azzera tutti i pixel che non sono effettivamente sopra una cresta in modo da fornire, in uscirà un insieme di linee: questo processo è detto non-maximal suppression. Quando viene lanciato l’algoritmo vengono scelti due valori di soglia diversi tra loro, T1 e T2, con T1 > T2. L’algoritmo parte da un valore di cresta con valore maggiore di T1, il tracking quindi va in entrambe le direzioni della cresta fino a che il valore di questa ultima non scenda sotto T2. Questo metodo garantisce il riconoscimento degli edge anche in coso di immagine rumorosa o casi in cui il bordo sia diviso in più frammenti distinti.
Utilizzo
L’effetto di questo algoritmo dipende da tre parametri: l’ampiezza del kernel gaussiano utilizzato nella prima fase di smoothing e le due soglie T1 e T2 usate dal tracker. Aumentare l’ampiezza della gaussiana riduce la sensibilità del metodo al rumore ma allo stesso modo l’immagine può perdere alcuni dettagli utili per il riconoscimento del bordo. Solitamente, il valore di T1 viene scelto abbastanza alto e il valore di T2 relativamente basso, infatti settare T2 ad un valore troppo alto rischia di rompere i bordi rumorosi, mentre un valore troppo basso rischi di rilevare bordi non importanti o inesistenti.
Esempio
Come esempio prendiamo la seguente immagine:

Usiamo un kernel gaussiano con deviazione standard a 1 e T1 = 255, T2 = 1. Otteniamo:
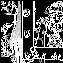
Gli edge principali sono stati rilevati, ma allo stesso modo sono stati rilevati molti dettagli trascurabili. Questo avviene perché il valore di T2 è troppo basso, ripetiamo l’analisi incrementando tale valore a 220:
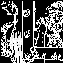
I bordi sono più rotti, inoltre gli edge verticali sul muro non sono stati rilevati, sintomo di un valore questa volta troppo alto. Riduciamo il valore di T1 a 128 e riportiamo il valore di T2 a 1, come nel primo esempio, inoltre aumentiamo la deviazione standard a 2.
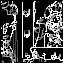
In questo modo ottengo una migliore rilevazione degli edge e allo stesso modo una minore sensibilità al rumore, ottengo quindi il risultato migliore.