- Definizione di allucinazione:
- Perché accadono:
Introduzione
Si parla di “allucinazioni” nei modelli di linguaggio (come GPT) quando l’IA genera risposte o informazioni che sembrano plausibili ma non sono vere o corrette. Ad esempio, se chiedi una ricetta inventata, l’IA può produrre una risposta come se fosse reale, anche se non ha basi nei dati su cui è stata addestrata. Queste accadono in quanto i Language Model sono addestrati a completare il testo basandosi su probabilità statistiche, senza un legame diretto con verità oggettive o morali. In altre parole, il loro scopo principale è proseguire il testo in modo coerente, non fornire risposte vere.
Cos’è un Language Model?
- È un sistema addestrato su grandi quantità di testo per prevedere la sequenza più probabile di parole. Funziona come una sorta di simulazione di tessuto nervoso, continuando il testo token per token (parola per parola o frammento per frammento).
- Non interagisce davvero con te: Quando parli con un modello come ChatGPT, in realtà non “conversa”, ma crea una simulazione probabilistica di una conversazione. Ad esempio, se gli dai un testo con un bot che risponde e poi scrivi “Utente dice: …”, il modello proseguirà anche la parte dell’utente. Capire questo concetto è fondamentale per capire cosa è veramente un Language Model. Ad esempio se chiedi una ricetta inventata (es. della “dammi la ricetta della carbonara della signora Pina”), il modello cerca di proseguire il testo come se quella ricetta esistesse.
Gli LLM possano generare informazioni plausibili ma errate, il cosiddetto “nonsense plausibile”. Queste non sono bug, ma una caratteristica intrinseca del modo in cui funzionano gli LLM.
Le allucinazioni come elemento naturale del modello
- Le allucinazioni non sono un “bug” ma una caratteristica naturale del modello. Il sistema non è progettato per “dire la verità” ma per proseguire il testo in modo statisticamente plausibile.
- Pensare a GPT un modello di linguaggio come una sorta di “compressione dell’Internet” (un enorme file zip): contiene informazioni statistiche su un’enorme quantità di testo, ma non garantisce precisione o verità.
- Le "allucinazioni" sono una conseguenza naturale del modo in cui funzionano i modelli di linguaggio, sono connaturate ad essi. Anzi, sono il motivo per cui sono così potenti. Esse permettono al sistema di essere creativo, ad esempio scrivere un sonetto originale o produrre contenuti in uno stile specifico: senza le allucinazioni sarebbe impossibile fare ciò.
- Limiti e contesto: Le allucinazioni diventano un problema solo quando si cerca di ottenere risposte affidabili o accurate in contesti critici.
Come si affrontano
Esistono vari approcci per ridurre o gestire le allucinazioni: a monte con il fine tuning, durante il prompt con il RAG o a valle con i guardrails o post-processing
1. Fine-tuning e Annotazione
- Il modello viene addestrato ulteriormente su set di dati annotati manualmente con risposte corrette o eticamente appropriate invece che essere addestrato solo su tutto internet senza filtri.
- Esempio: I GPT 3 iniziali potevano rispondere a domande su temi eticamente discutibili senza filtri. Oggi, grazie all’addestramento con testi scritti da annotatori umani, evitano queste risposte.
2. Retrieval-Augmented Generation (RAG) (o Grounding)
- Arricchire il prompt con informazioni reali di contesto.
- Ad esempio, prima di rispondere a una domanda, il sistema esegue una ricerca in archivi o database specifici per ottenere il contesto. Questo contesto viene poi incluso nel prompt per aiutare il modello a rispondere basandosi su informazioni reali.
- Fornendo quindi sia la domanda che la risposta nel prompt il Language Model non deve inventarseli ma deve solo recuperare informazioni che ha già.
3. Guardrails (Barriere di sicurezza)
- Si costruiscono barriere intorno al modello, imponendo limiti su certi tipi di risposte, quindi è sempre un arricchimento del prompt come sopra ma non con informazioni di contesto ma con dei limiti che devono essere rispettati.
- Esempio: Prompt che includono regole del tipo “Rispondi solo sulla base di questi contenuti”.
4. Controllo a valle (Post-processing)
- Una volta generata la risposta, viene controllata per verificarne la coerenza con i dati di partenza.
- Esempio: Si verifica se la risposta è deducibile da un documento specifico o se tocca argomenti sensibili, per bloccarla o correggerla.
Approfondimento geometrico
Cosa è un modello
Un modello è una funzione che approssima un andamento estratto dai dati, ovvero una rappresentazione statistica della realtà. Quando parliamo di un modello, ci riferiamo a un sistema che prende in ingresso dei dati e restituisce una stima di un valore d’uscita.
Nell’immagine sotto i punti neri sono i dati presi dal mondo reale mentre la curva blu è l’approssimazione del modello.
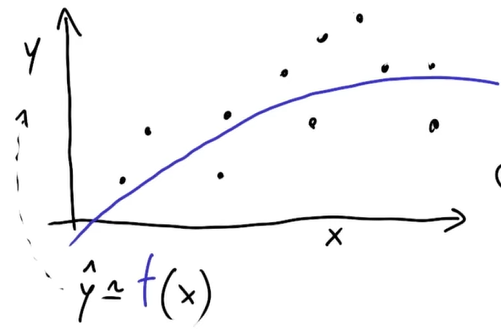 Un modello è quindi:
Un modello è quindi:
- Un’approssimazione: il modello cerca di adattarsi ai dati, ma non è una rappresentazione perfetta della realtà.
- È definito su tutto lo spazio: mentre i dati di addestramento sono punti discreti raccolti dal mondo reale, il modello generalizza e definisce una funzione continua anche dove non ho informazione. Questa seconda caratteristica è fondamentale per comprendere le allucinazioni: il modello esiste e opera anche in regioni dello spazio in cui non ci sono dati di addestramento diretti, portandolo a produrre output “inventati”.
Come si crea un modello
Un modo per costruire questi modelli è utilizzare reti neurali, che sono simulazioni del tessuto nervoso biologico. Spesso si parla di black box perché la loro complessità rende difficile interpretare esattamente come arrivano alle loro previsioni. Le reti neurali sono strutturate in strati di neuroni, che si scambiano segnali attraverso connessioni ponderate da parametri numerici chiamati pesi. L’apprendimento avviene aggiustando questi pesi per migliorare la capacità del modello di approssimare i dati.
Stratificazione delle informazioni
 Le reti neurali hanno un’organizzazione gerarchica in cui i neuroni più superficiali hanno a che fare con quanto inserito dall’utente mentre più si va a fondo più si perde la relazione con l’input dell’utente e i pesi diventano più “astratti”.
Si chiama deep learning proprio perché è deep, quindi gli strati della rete sono molto profondi.
Le reti neurali hanno un’organizzazione gerarchica in cui i neuroni più superficiali hanno a che fare con quanto inserito dall’utente mentre più si va a fondo più si perde la relazione con l’input dell’utente e i pesi diventano più “astratti”.
Si chiama deep learning proprio perché è deep, quindi gli strati della rete sono molto profondi.
- Strati iniziali: interagiscono direttamente con l’input
- Immagine: i pixel di una immagine, i bordi…
- Testo: accostamento tra sillabe
- Strati intermedi: elaborano rappresentazioni più astratte
- Immagine: pattern di colore, orientamenti…
- Testo: strutture grammaticali
- Strati finali: catturano concetti di livello più alto
- Immagine: oggetti astratti
- Testo: strutture semantiche
Come funziona un LLM
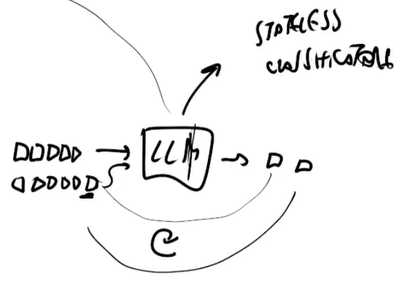
I Language Model, sono come dei classificatori il cui compito è:
- Ogni sequenza di testo (prompt) viene rappresentata in uno spazio multi-dimensionale.
- Il modello cerca di prevedere il token successivo, suddividendo lo spazio in zone corrispondenti alle possibili continuazioni.
Quando si interagisce con un modello di linguaggio, ogni input viene trasformato in un punto nello spazio dei dati. Il modello, in base alla sua struttura interna e all’addestramento ricevuto, determina quale sia il token più probabile per proseguire la sequenza.
Nell’esempio sotto si vede uno spazio tridimensionale (nella realtà è uno spazio a quasi infinite dimensioni) dove ogni punti rappresenta un prompt (che è formato da una serie di token) e il classificatore deve raggruppare tutti i prompt in base al token successivo.
Per esempio tutti i prompt del primo insieme forniranno come token successivo “il”, tutti i prompt nel secondo insieme “!-” e così via.
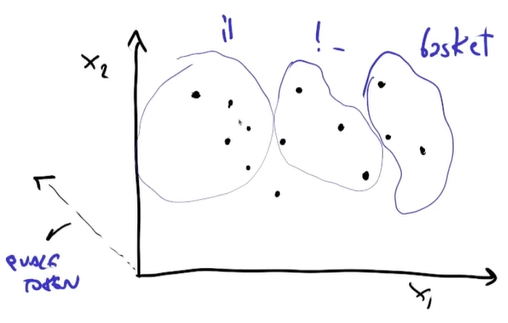 Questo processo avviene iterativamente: il token generato viene reimmesso nel modello, che cerca di trovare il token successivo più probabile e coaì via.
Questo processo avviene iterativamente: il token generato viene reimmesso nel modello, che cerca di trovare il token successivo più probabile e coaì via. - Ogni parola viene scelta tra circa 880.000 token possibili.
- I testi con significati simili vengono collocati in regioni vicine dello spazio del modello.
Allucinazione
Abbiamo detto che il modello divide lo spazio in regioni e assegna a ogni punto una previsione, che è il token successivo che dovrà fornire. Tuttavia, ci sono aree dello spazio in cui il modello non ha esempi diretti dai dati di addestramento, eppure il modello ha diviso comunque tutto lo spazio in zone, indipendentemente che ci siano dati o meno, semplicemente la divisione non sarà così accurata. Quando il modello genera una risposta in una di queste zone, non ha un riferimento reale, e quindi si “inventa” un output coerente con la sua struttura interna, ma non necessariamente corretto rispetto alla realtà.
Se chiediamo:
“Scrivi un sonetto in stile Eminem su un cucchiaio di legno”
È improbabile che il modello abbia visto un esempio simile nei dati di addestramento. Tuttavia, è in grado di generalizzare e creare un testo coerente, basandosi sulle sue rappresentazioni interne di “sonetto”, “stile Eminem” e “cucchiaio di legno”.
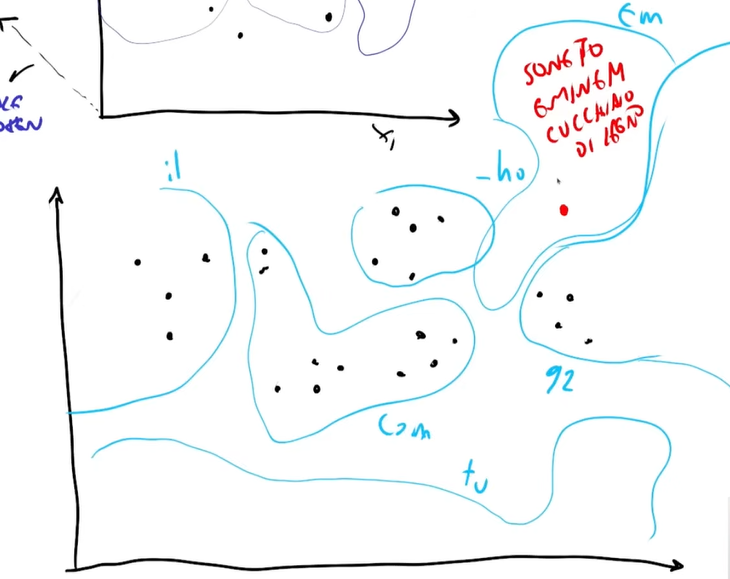
Da un punto di vista geometrico, il modello sta lavorando in una zona dello spazio senza dati diretti, ma continua a produrre output basandosi sulle informazioni che ha a disposizione.
A questo punto, è chiaro che l’allucinazione non è un errore, ma una proprietà fondamentale del modello. È proprio questa capacità di interpolare e generare testo in zone di spazio non mappate direttamente che rende i Language Model così potenti. Da un lato, ciò permette loro di essere creativi. Dall’altro, significa che le loro risposte non devono essere interpretate come verità assolute. Allucinazione e creatività in un LLM sono la stessa identica cosa.