Gli iperparametri sono parametri esterni al modello stesso che influenzano il processo di addestramento e la sua capacità di apprendimento. Quindi, mentre i "parametri" del modello sono quelli interni che vengono appresi durante il processo di addestramento, gli "iperparametri" sono quelli che impostiamo manualmente prima di addestrare il modello.
Un esempio comune di iperparametro è la “velocità di apprendimento” del gradient descent. Questo iperparametro determina quanto velocemente il modello dovrebbe imparare dai dati. Se lo impostiamo troppo alto, potremmo saltare troppo in fretta e non riuscire a convergere verso una soluzione ottimale. Se è troppo basso, il modello potrebbe impiegare molto tempo per imparare o potrebbe rimanere bloccato in minimi locali.
Un altro esempio è la profondità di un Decision tree.
Trovare i migliori iperparametri
Ora che sappiamo cos’è un iperparametro, come possiamo trovare i migliori valori per essi? Ci sono diverse tecniche che possiamo utilizzare per ottimizzare gli iperparametri e migliorare le prestazioni del nostro modello.
Ricerca a griglia
In questa tecnica, definiamo una griglia di valori per ciascun iperparametro che vogliamo ottimizzare. Ad esempio, se abbiamo due iperparametri da regolare, possiamo creare una griglia con diverse combinazioni di valori per ciascuno di essi. Quindi, addestriamo e valutiamo il modello utilizzando tutte queste combinazioni di iperparametri e scegliamo quella che restituisce le migliori prestazioni.
L’approccio è quindi piuttosto semplice: si tratta di una ricerca esaustiva a forza bruta tra un elenco di valori definiti.
Sebbene la ricerca a griglia sia un approccio potente per la ricerca del set ottimale dei parametri, la valutazione di tutte le possibili combinazioni dei parametri può essere molto costosa dal punto di vista computazionale. Un approccio alternativo al campionamento delle varie combinazioni di parametri utilizzando scikit-learn è la ricerca casuale.
Ricerca casuale
Un’altra tecnica è la “ricerca casuale” o “random search”. Invece di esaminare tutte le combinazioni possibili di iperparametri, selezioniamo casualmente un certo numero di configurazioni e le valutiamo.
Utilizzando la classe RandomizedSearchCV, possiamo estrarre combinazioni parametri casuali dalla distribuzione di campionamento sulla base di un determinato budget.
Anche se potremmo non esplorare tutte le possibili combinazioni, questa tecnica può essere più efficiente in termini di tempo computazionale e può ancora fornire buoni risultati.
Ricerca bayesiana
Una terza tecnica è la “ricerca bayesiana”, che utilizza metodi di ottimizzazione bayesiana per selezionare le configurazioni degli iperparametri da provare. Questo approccio cerca di trovare le migliori configurazioni in modo più efficiente, concentrandosi sulle aree dello spazio degli iperparametri che promettono i migliori risultati.
Convalida incrociata nidificata
La convalida incrociata nidificata incorpora sia la convalida incrociata che la ricerca degli iperparametri in un’unica procedura. Nella convalida incrociata nidificata, abbiamo un ciclo di convalida incrociata k-fold esterno per suddividere i dati fra le parti di addestramento e di test, più un ciclo interno che viene utilizzato per selezionare il modello utilizzando la convalida incrociata k-fold sulla parte di addestramento. Dopo la selezione del modello, la parte di test viene utilizzata per valutare le prestazioni del modello. La figura spiega il concetto della convalida incrociata nidificata con cinque parti esterne e due parti interne, il che può essere utile per grossi dataset nei quali le prestazioni computazionali sono importanti. Questo specifico tipo di convalida incrociata nidificata è chiamata anche convalida incrociata 5x2.
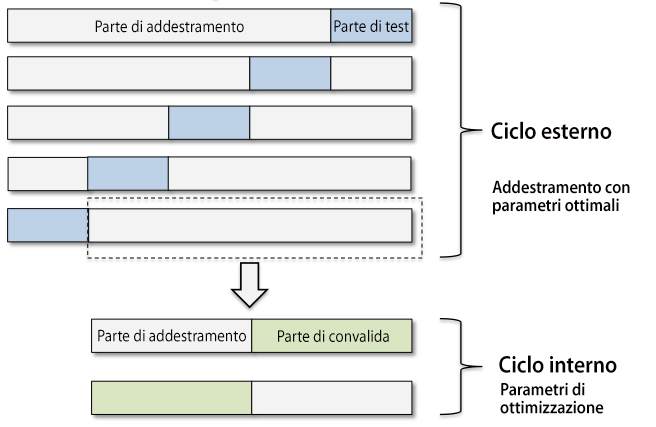
Funziona in questo modo:
- Dividiamo il nostro dataset in più fold (partizioni) esterne. Ogni fold rappresenta un insieme di dati di test indipendente.
- Per ogni fold esterno:
- Dividiamo i dati rimanenti (non inclusi nel fold esterno) in k-fold interni.
- Eseguiamo la ricerca degli iperparametri utilizzando la convalida incrociata k-fold sui fold interni. Questo ci fornisce una stima delle prestazioni del modello con diverse configurazioni di iperparametri su dati indipendenti.
- Scegliamo la configurazione di iperparametri che ha prodotto le migliori prestazioni medie sui fold interni.
- Utilizziamo questa configurazione di iperparametri per addestrare il modello sul fold esterno e valutiamo le sue prestazioni su questo insieme di dati di test indipendente.
Questa procedura ci consente di ottimizzare gli iperparametri mentre manteniamo una valutazione accurata delle prestazioni del modello su dati indipendenti. Evita anche la contaminazione dei dati di test durante il processo di ricerca degli iperparametri, il che potrebbe portare a una valutazione distorta delle prestazioni del modello.
La convalida incrociata nidificata è particolarmente utile quando abbiamo un numero limitato di dati e vogliamo massimizzare l’uso di ciascun campione per l’addestramento e la valutazione del modello. Inoltre, fornisce stime più affidabili delle prestazioni del modello rispetto alla semplice convalida incrociata k-fold, poiché sfrutta più volte i dati in modo efficiente.