Questa nota prende a piene mani dal corso Getting Started: Clean Architecture in .NET
Introduzione
L’architettura di un software può essere definita come viene strutturato il software stesso, sia a livello di cartelle e file ma soprattutto a livello logico: suddividere il codice in livelli logici omogenei in modo che siano analizzabili senza scendere nei dettagli. Permette inoltre di prendere un componente del nostro sistema e capire come è fatto in quanto questo segue una sorta di blueprint. Le decisioni sull’architettura sono tipicamente lunghe e costose da modificare per cui sono di vitale importanza e necessitano di esperienza.
Analogamente ai design pattern della GoF esistono anche i pattern per quanto riguarda l’architettura del software, in particolare:
Richard Taylor
quote::“Architectural pattern is a general, reusable resolution to a commonly occouring problem in software architecture within a given context.“
Clean architecture è un’architettura Domain Centric.
Definizione
Clean architecture separa il software in livelli in cui le dipendenza puntano tutte dall’esterno verso l’interno. I livelli interno contengono la business logic mentre i livelli esterni il database e le interazioni con il mondo esterno.
Applicazione di esempio
In questo corso costruiremo un’applicazione per la gestione, dal punto di vista dell’amministratore, di un sistema di gestione di corsi all’interno di palestre.
Inoltre ogni admin avrà un livello di abbonamento a cui corrisponderanno delle cose che può/non può fare; per esempio nel livello free l’admin può gestire una sola palestra con una sola stanza e massimo 4 corsi, nel livello pro di più e così via.
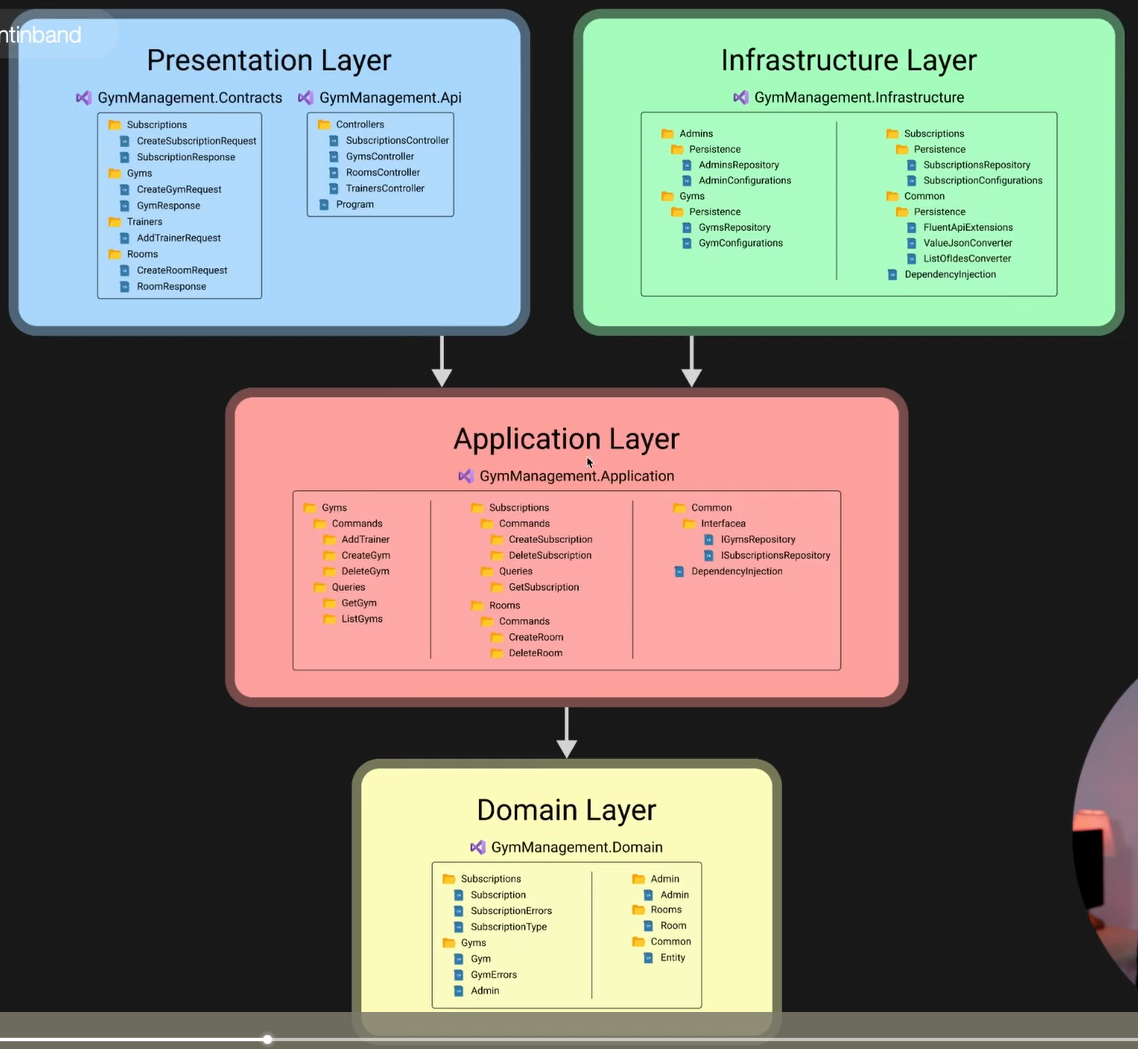 Creo una cartella che conterrà la soluzione con all’interno una cartella
Creo una cartella che conterrà la soluzione con all’interno una cartella src per i vari livelli.
Nella cartella src creo i vari livelli, in particolare uno sarà di tipo webapi mentre gli altri class library.
dotnet new webapi -o GymManagement.Api
dotnet new classlib -o GymManagement.Application
dotnet new classlib -o GymManagement.Infrastructure
dotnet new classlib -o GymManagement.Domain
dotnet new classlib -o GymManagement.ContractsPoi creo già a priori le dipendenze come da immagine sopra:
dotnet add GymManagement.Api reference GymManagement.Application
dotnet add GymManagement.Infrastructure reference GymManagement.Application
dotnet add GymManagement.Application reference GymManagement.Domain
dotnet add GymManagement.Api reference GymManagement.ContractsInfine nella cartella del progetto creo la soluzione
dotnet new sln --name "GymManagement"
dotnet sln add (ls -r **/**.csproj)Layers
Presentation
- Gestisce l’interazione con il mondo esterno
- Mostra i dati, per esempio fornendo la view
- Traduce i dati per mostrarli all’utente
- Gestisce la UI e gli elementi che sono riferiti al framework scelto
- Converte i dati dal mondo dell’utente alle strutture dati interne dell’applicativo, tipicamente mediante il pattern Mediator
Infrastructure
- Comunica con il database o altri servizi
Application
- Eseguire i casi d’uso dell’applicazione
- Ottiene gli oggetti del dominio
- Manipolare gli oggetti del dominio
Domain
- Definisce i modelli del dominio
- Definisce gli errori
- Esegue la business logic
- Fa rispettare le regole di business
Pattern
CQRS
Il pattern CQRS in una frase “divide le letture dalle scritture”, in particolare i metodi che modificano gli oggetti sono detti Commands mentre i metodi che interrogano sono detti Query.
 Per esempio invece di avere una classe
Per esempio invece di avere una classe GymService con i metodi CreateGym, DeleteGym e GetGym avrò due classi, una per le scrittura chiamata GymWriteService con solo i metodi CreateGym e DeleteGym e una per la lettura chiamata GymReadService con il metodo GetGym.
Salendo di livello posso avere una classLibrary Application solo per le letture e un’altra solo per le modifiche.
CQS
CQS significa Command Query Separation è un stile di scrittura sottoinsieme del CQRS che prevede:
- I metodi che manipolano i dati ritornano
void - I metodi in lettura non manipolano alcun dato e ritornano un valore. Per esempio il metodo
Gym CreateGym(string name);è invalido in quanto essendo un metodo che manipola i dati deve ritornare void.
Mediator
E’ un pattern in cui invece di avere due oggetti che comunico direttamente tra di loro comunico tramite un mediator in mezzo tra i due. Questo per aumentare il disaccoppiamento tra due classi e renderle più indipendenti l’una dell’altra.
 Nell’esempio sotto si vede solo stesso senza mediator (metodo classico) e con mediator.
Nell’esempio sotto si vede solo stesso senza mediator (metodo classico) e con mediator.
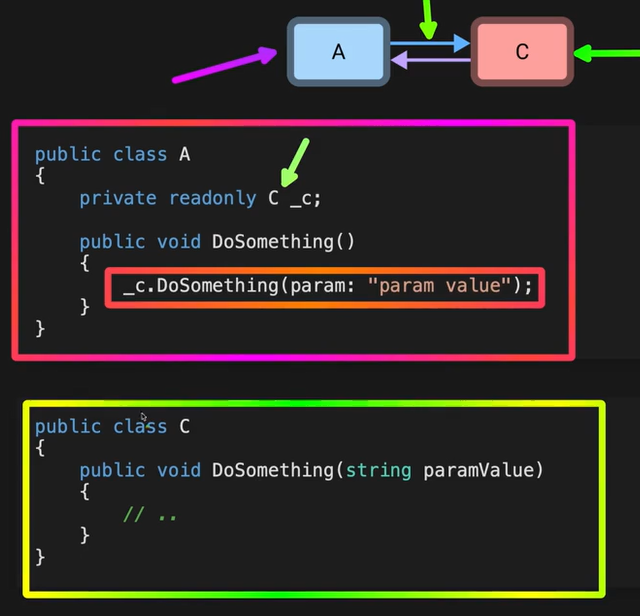
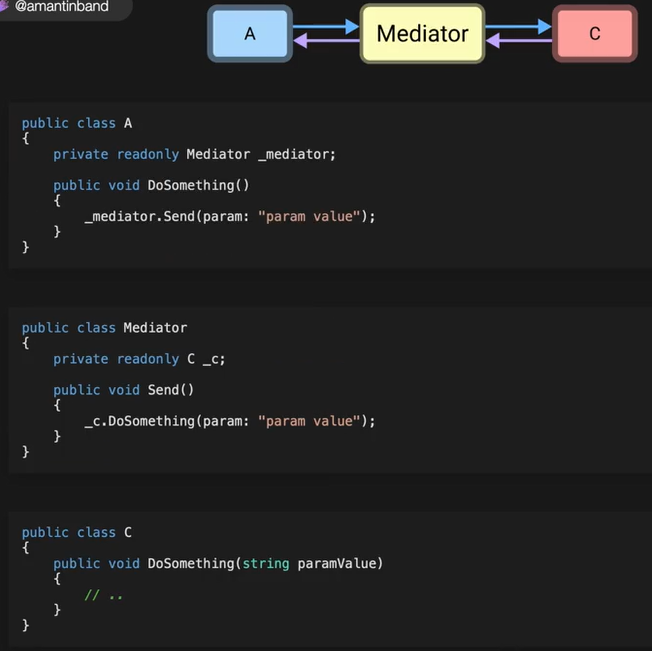 Per esempio l’API non chiamerà direttamente i metodi dell’
Per esempio l’API non chiamerà direttamente i metodi dell’Application ma chiamerà i metodi del mediator (un pacchetto nuget famoso per questo è MediatR) il quale chiamerà i metodi effettivi dell’Application. In questo modo l’API non sa quali metodi effettivi chiamerà dell’Application ma saranno mascherati dal Mediator.
Repository Pattern
Il Repository Pattern è un pattern di progettazione utilizzato per separare la logica di accesso ai dati dalla logica di business dell’applicazione. Fornisce un’interfaccia centrale per eseguire operazioni sui dati (come CRUD), nascondendo i dettagli dell’implementazione (ad esempio, l’accesso al database o l’ORM utilizzato). Obiettivi:
- Isolamento: Decoupla la logica di business dai dettagli di accesso ai dati.
- Testabilità: Facilita l’uso di mock o finti repository nei test.
- Manutenibilità: Centralizza la gestione delle query e delle interazioni con il database.
Esempio sul giro che viene fatto quando viene creata una nuova Subscription.
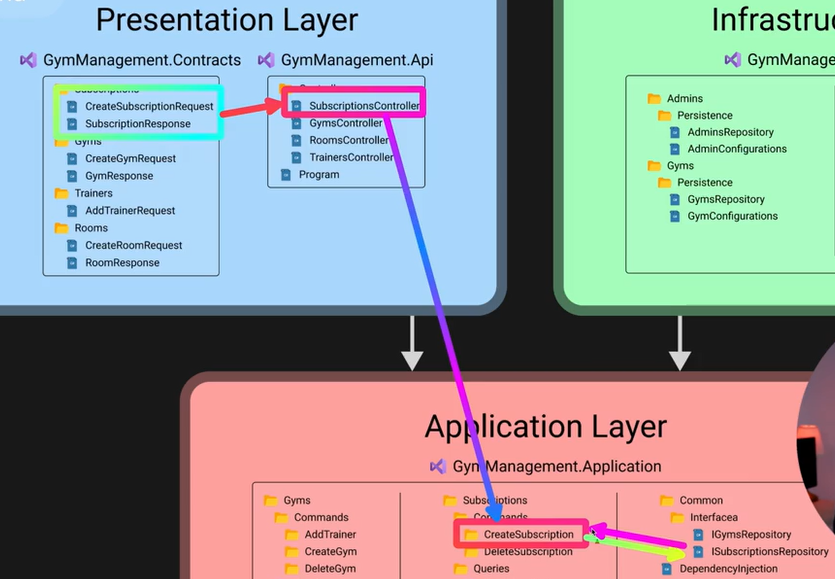 L’implementazione effettiva della repository sarà a livello di
L’implementazione effettiva della repository sarà a livello di Infrastructure.
Unit of Work Pattern
Il Unit of Work Pattern è un pattern di progettazione che gestisce un gruppo di operazioni correlate come un’unica unità transazionale. Lavora spesso insieme al Repository Pattern, coordinando le interazioni con diversi repository e garantendo che tutte le modifiche vengano salvate nel database in modo atomico. Obiettivi:
- Transazioni: Assicura che tutte le operazioni vengano salvate in modo coerente.
- Isolamento: Centralizza la gestione del contesto.
- Performance: Riduce il numero di connessioni al database raggruppando operazioni multiple.
Tipicamente viene iniziata una transaction da qualche parte nella definizione della classe
IUnitOfWorke viene committata quando viene chiamato un metodo specifico, per esempio_unitOfWork.CommitChangesAsync()
Domain Driven Design
Sono tutte le pratiche per sviluppare il livello di Domain, in particolare è un approccio per sviluppare sistemi complessi in cui l’enfasi è sul dominio su cui stiamo sviluppando. E’ un insieme di pratiche, terminologie, linee guida e concetti. L’obiettivo è rendere il codebase molto più facile da lavorarci, quindi estendibile e mantenibile. Un Domain Model è un oggetto che rappresenta un oggetto del dominio dell’applicazione e contiene sia property che metodi.
Anemic vs Rich
L’Anemic Domain Model e il Rich Domain Model sono due approcci per strutturare il dominio in un’applicazione orientata agli oggetti in particolare l’Anemic Domain Model separa dati e logica di business, mantenendo i modelli semplici ma spostando la logica nei servizi, ideale per applicazioni CRUD semplici.
Tipicamente questo viene fatto esponendo i dati all’esterno tramite property public.
Il Rich Domain Model incapsula dati e logica nel modello stesso, migliorando coesione e mantenibilità, ed è più adatto per domini complessi con regole intricate.
Questo avviene tramite
- Property e field private di default;
- Espone all’esterno solo il minimo indispensabile
Always Valid vs Not Always Valid
Un Always Valid Domain Model garantisce che un’entità sia sempre in uno stato valido, applicando le regole di business direttamente all’interno del modello. Ciò migliora la coesione e previene stati incoerenti. Al contrario, un Not Always Valid Domain Model permette stati temporaneamente non validi, spostando la responsabilità della validazione all’esterno, solitamente nei servizi. E’ una best practice scrivere codice in modalità Always Valid Domain Model.
Persistence ignorance
La Persistence Ignorance è un principio di progettazione che separa il modello di dominio dai dettagli di persistenza, come database o ORM. Le entità e le regole di business non devono dipendere da tecnologie specifiche di persistenza, rendendo il dominio più flessibile, testabile e indipendente dall’infrastruttura.
Error handling
Presentation
- Una delle responsabilità del livello di
Presentationè convertire i dati forniti dall’utente in modo che siano nelle strutture dati diApplication. Qualora i dati non siano convertibili o siano invalidi non devo andare all’Applicationma sarà direttamente il livello diPresentationche fornirà 400 senza proseguire oltre. - Anche qualora l’utente cerchi di interagire con qualcosa che non esiste (esempio pagine o API che non esistono) sarà sempre il livello di
Presentationche fornirà 400. - Se l’utente invece non è autenticato il livello di
Presentationfornirà 401. - Convertire gli errori dell’
Applicationin errori per il mondo esterno.
Application
- Verifica che i dati che riceve dal livello di
Presentationsiano validi, in caso contrario eccezioni o errori di validazione che verranno convertiti in 400 error dalPresentation; - Talvolta converte degli errori forniti dal
Domainin errori diversi da fornire alPresentation; - Converte gli errori o i
nullforniti dal livello diInfrastructurein errori da fornire alPresentation;
Domain
- Gestisce che le regole di business della mia applicazione venga rispettate e, in caso contrario, fornirà un errore al livello di
Application, la quale o lo propagherà a livello diPresentationoppure lo convertirà. Esempio di regola di business nell’applicazione delle palestre è che nel livello free posso avere al massimo una stanza da gestire. - Errori durante la modifica degli oggetti di domain
- Il livello di
Domainè esplicito sull’errore che ha trovato, eventualmente saranno gli altri livelli a mascherarlo.
Error flow
Potrei usare le eccezioni ma hanno il problema per cui il livello Presentation o Application deve conoscere tutte le possibili eccezioni che possono essere fornire dal Domain e gestirle una ad una di conseguenza.
Un’approccio migliore è utilizzare il Result Pattern per gli errori che mi aspetto che possano accadere: il Domain non fornirà un’eccezione ma un errore preso da un insieme di tutti gli errori definiti che possono essere forniti da quest ultimo.
Il livello di Application prenderà tale Result e o lo propagherà direttamente al livello di Presentation oppure lo modificherà in base al flusso.
Per gli errori che non mi aspetto possano accadere ma accadranno in caso di bug utilizzerò correttamente le Exception.
Esempio
Esempio di gestione del flusso degli errori usando il Result Pattern con MediatR
[HttpPost]
public async Task<IActionResult> CreateGym(
CreateGymRequest request,
Guid subscriptionId)
{
var command = new CreateGymCommand(request.Name, subscriptionId);
// Lancio il comando all'Application il quale fornirà una Gym se tutto bene, altrimenti una lista di errori
var createGymResult = await _mediator.Send(command);
// Permette di verificare che createGymResult sia senza errori, in caso affermativo chiama la prima lamda altrimenti la seconda.
// In questo caso la seconda lamda è il metodo "Problem" fatto da me che permette di convertire gli errori di livello Application in StatusCode per il presentation return createGymResult.Match(
gym => CreatedAtAction(
nameof(GetGym),
new { subscriptionId, GymId = gym.Id },
new GymResponse(gym.Id, gym.Name)),
Problem);
}
protected IActionResult Problem(List<Error> errors)
{
if (errors.Count is 0)
return Problem();
if (errors.All(error => error.Type == ErrorType.Validation))
return ValidationProblem(errors);
return Problem(errors[0]);
}
private ObjectResult Problem(Error error)
{
var statusCode = error.Type switch
{
ErrorType.Conflict => StatusCodes.Status409Conflict,
ErrorType.Validation => StatusCodes.Status400BadRequest,
ErrorType.NotFound => StatusCodes.Status404NotFound,
_ => StatusCodes.Status500InternalServerError
};
return Problem(statusCode: statusCode, detail: error.Description);
}
private IActionResult ValidationProblem(List<Error> errors)
{
var modelStateDictionary = new ModelStateDictionary();
foreach (var error in errors)
modelStateDictionary.AddModelError(
error.Code,
error.Description);
return ValidationProblem(modelStateDictionary);
}Tips & Tricks
Dependency Injection
In Program.cs tipicamente vanno esplicitate tutte le istanze concrete delle interfacce che verranno istanziate tramite Dependency Injection.
Questo però è scomodo in quanto vado a “sporcare” il Program.cs con tutte le implementazioni di tutte le classi.
Un trucco è creare delle extension methods nei vari progetti che dichiarano loro la DI sulle classi che interessano.
Per esempio nel progetto GymManagement.Application
public static IServiceCollection AddApplication(this IServiceCollection services)
{
services.AddScoped<ISubscriptionsService, SubscriptionsService>();
// Tutte le altre DI...
return services;
}e in Program.cs avrò:
builder.Services
.AddApplication()
// Unico metodo dell'infrastructure layer usato dal Presentation Layer
.AddInfrastructure()
.Add...();Utilizzare un enum in presentation e domain
- Uno dei compiti principali del livello di Presentation è convertire i dati nel formato richiesto dalla Business Logic o dal Domain.
- I tipi di dato definiti nel livello di Presentation non possono essere direttamente passati all’Application o al Domain, perché questi livelli non dipendono dal Presentation e quindi non li riconoscono.
- È responsabilità del Presentation, che dipende dal Domain, effettuare le conversioni necessarie.
Esempio pratico: gestione di un enum
Immaginiamo di avere un enum definito a livello di API nel livello di Presentation:
public enum SubscriptionType
{
Free,
Starter,
Pro
}Se dobbiamo passare un valore di questo tipo all’Application, è necessario convertirlo in un tipo di dato che l’Application riconosca. Una buona pratica è definire un Smart Enum a livello di Domain. Nel Domain, possiamo definire uno Smart Enum come segue:
public class SubscriptionType(string name, int value) : SmartEnum<SubscriptionType>(name, value)
{
public static readonly SubscriptionType Starter = new(nameof(Starter), 1);
public static readonly SubscriptionType Pro = new(nameof(Pro), 2);
}Questo approccio consente di rappresentare i tipi di sottoscrizione con una maggiore flessibilità, includendo metadati o logica associata. Nel livello di Application, è possibile convertire il tipo ricevuto dal Presentation in un tipo riconosciuto dal Domain:
if (!DomainSubscriptionType.TryFromName(
request.SubscriptionType.ToString(),
out var subscriptionType))
{
return Problem(
statusCode: StatusCodes.Status400BadRequest,
detail: "Invalid subscription type");
}