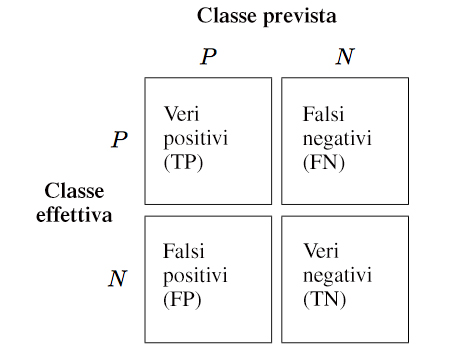
La matrice di confusione è uno strumento utile nell’ambito della valutazione delle performance di un modello di Classificazione.
Essa mostra quanti elementi di ciascuna classe sono stati classificati correttamente e quanti sono stati erroneamente classificati.
La matrice di confusione è semplicemente una matrice quadrata che rileva il conteggio dei veri positivi e dei veri negativi, dei falsi positivi e dei falsi negativi nelle previsioni di un classificatore
Esempio
Immagina di avere un modello che deve distinguere tra gatti e cani basandosi su immagini. La matrice di confusione ti aiuta a capire quante volte il modello ha fatto predizioni corrette e quante volte ha commesso errori, indicando se ha confuso gatti con cani o viceversa.
Supponiamo che abbiamo 10 immagini:
- 4 immagini di gatti che il modello ha correttamente identificato come gatti.
- 3 immagini di cani che il modello ha correttamente identificato come cani.
- 1 immagini di gatti che il modello ha erroneamente classificato come cani.
- 2 immagine di cane che il modello ha erroneamente classificato come gatto.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report, ConfusionMatrixDisplay
# Dati di esempio
y_true = np.array([1, 0, 1, 1, 0, 0, 1, 0, 1, 0]) # Vero: 1=Gatto, 0=Cane
y_pred = np.array([1, 0, 1, 0, 0, 1, 1, 0, 1, 1]) # Predetto: 1=Gatto, 0=Cane
# 1 volta ho predetto cane e invece era gatto
# 2 volte ho predetto gatto ed era cane
# Creare la matrice di confusione
conf_matrix = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix,display_labels=["Cane", "Gatto"])
disp.plot()
plt.show() La matrice di confusione visualizzata è la seguente:
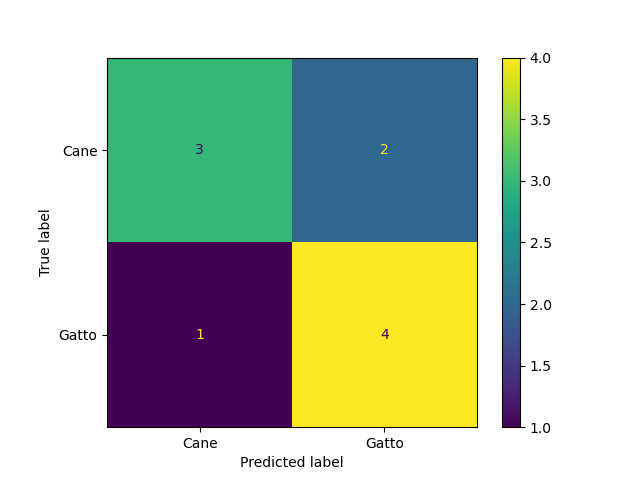 Si nota che 2 volte ho predetto “Gatto” e invece era “Cane” e 1 volta ho predetto “Cane” e invece era “Gatto”.
Si nota che 2 volte ho predetto “Gatto” e invece era “Cane” e 1 volta ho predetto “Cane” e invece era “Gatto”.