Un algoritmo di decision tree (albero decisionale) è un metodo utilizzato nel campo del machine learning per la Classificazione e la Regressione. Si basa su una struttura a forma di albero in cui ogni nodo rappresenta una domanda su una caratteristica dei dati, e i rami rappresentano le possibili risposte a questa domanda. Alla fine di ogni percorso attraverso l'albero si raggiunge una foglia che rappresenta una decisione o una previsione.
Per comprendere meglio come funziona un algoritmo di decision tree, immaginiamo di dover prendere una serie di decisioni basate su un insieme di caratteristiche o attributi. Ad esempio, potremmo dover decidere se portare un ombrello o meno in base alle condizioni meteorologiche. Le caratteristiche in questo caso potrebbero includere il tipo di nuvole nel cielo, la temperatura e la previsione di pioggia.
Per creare un albero decisionale, l'algoritmo cerca di trovare le domande che dividono meglio i dati in classi o categorie omogenee. In altre parole, cerca di porre le domande che separano meglio gli esempi di dati in gruppi che sono il più possibile simili all'interno dello stesso gruppo e il più possibile diversi tra gruppi diversi.
L’algoritmo inizia con tutti i dati nell’insieme di addestramento e cerca di suddividerli in gruppi più piccoli in base alle caratteristiche dei dati (fitting). Per fare ciò, valuta ogni possibile domanda che potrebbe essere posta su una caratteristica dei dati e sceglie quella che massimizza la purezza dei gruppi risultanti. La purezza si riferisce al grado in cui i dati in ciascun gruppo appartengono alla stessa classe o categoria.
Una volta posta una domanda, l’algoritmo separa i dati in base alla risposta alla domanda e continua il processo ricorsivamente per ciascun sottoinsieme di dati. Questo processo continua fino a quando non si raggiunge una condizione di arresto, come ad esempio quando tutti i dati in un nodo sono della stessa classe o quando non ci sono più domande da porre.
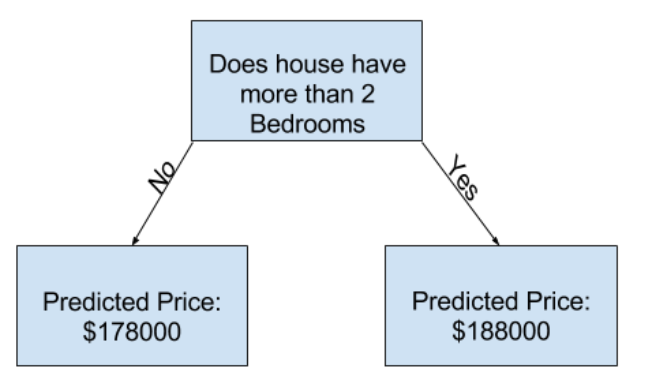
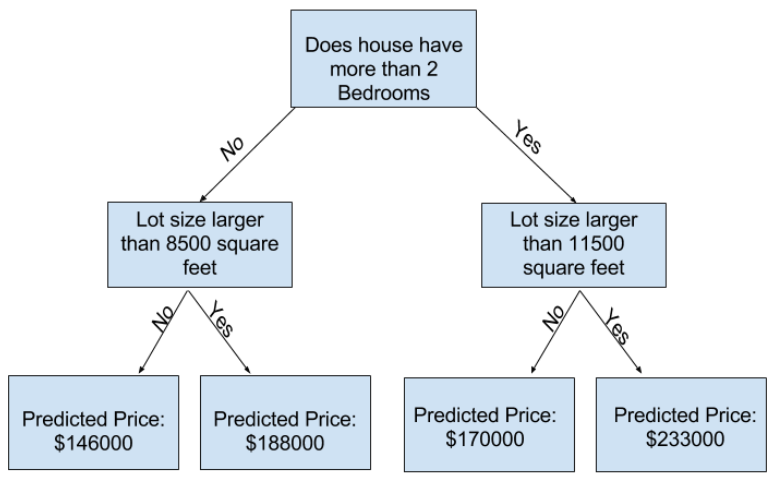
Più livelli ha un albero più sono le caratteristiche che va a considerare nel dataset. Per esempio in questo caso l’albero decisionale per il calcolo del prezzo di una casa considera il numero di camere e il lot size, conseguentemente ha una profondità di 2.
Inferenza
Quando l’albero decisionale è stato costruito, può essere utilizzato per fare previsioni su nuovi dati. Questo viene fatto seguendo il percorso dall’alto verso il basso attraverso l’albero, rispondendo alle domande in base alle caratteristiche del nuovo dato fino a quando si raggiunge una foglia, che fornisce la previsione o la decisione finale.
Gli alberi decisionali offrono diversi vantaggi nel contesto del machine learning. Sono relativamente facili da interpretare e visualizzare, il che li rende utili per capire come vengono prese le decisioni. Possono anche gestire sia dati categorici che numerici e sono abbastanza robusti rispetto ai dati rumorosi o mancanti.
Tuttavia, gli alberi decisionali possono anche essere suscettibili all’Overfitting, specialmente se non vengono controllati adeguatamente. L’overfitting si verifica quando l’albero si adatta troppo ai dati di addestramento e non generalizza bene ai nuovi dati, per esempio quando è troppo profondo.
Un metodo banale per limitare la profondità dell’albero è usare il parametro max_leaf_nodes di DecisionTreeRegressor ma un metodo sicuramente più veloce è passare al Random Forests.