Un database vettoriale è un ==tipo di database pensato per memorizzare vettori ad alta dimensione, tipicamente degli Embeddings==.
Ogni vettore ha un certo numero di dimensioni, che possono variare da decine a migliaia, a seconda della complessità e granularità dei dati.

I vettori vengono generalmente generati applicando una sorta di ==funzione di embedding sui dati grezzi==, come testo, immagini, audio, video e altri.
Il vantaggio principale di un database vettoriale è che consente una ricerca rapida e accurata della somiglianza e il recupero dei dati in base alla loro distanza vettoriale o somiglianza. Ciò significa che invece di utilizzare i metodi tradizionali di interrogazione dei database basati su corrispondenze esatte o criteri predefiniti, è possibile utilizzare un database vettoriale per trovare i dati più simili o pertinenti in base al loro significato semantico o contestuale.
==Per eseguire la ricerca e il recupero di similarità in un database vettoriale, è necessario utilizzare un vector query che rappresenti le informazioni o i criteri desiderati. Il vector query può essere derivato dallo stesso tipo di dati dei vettori memorizzati (ad esempio, utilizzando un'immagine come query per un database di immagini) o da diversi tipi di dati (ad esempio, utilizzando il testo come query per un database di immagini ). Quindi, è necessario utilizzare una misura di similarità che calcoli la vicinanza o la distanza di due vettori nello spazio vettoriale==. La misura della somiglianza può essere basata su varie metriche, come la Cosine Similarity, la distanza euclidea, la distanza di Hamming, l’indice di Jaccard.
Il risultato della ricerca e del recupero della somiglianza è solitamente un elenco classificato di vettori che hanno i punteggi di somiglianza più alti con il vettore della query. È quindi possibile accedere ai dati grezzi corrispondenti associati a ciascun vettore dall’origine o dall’indice originale.
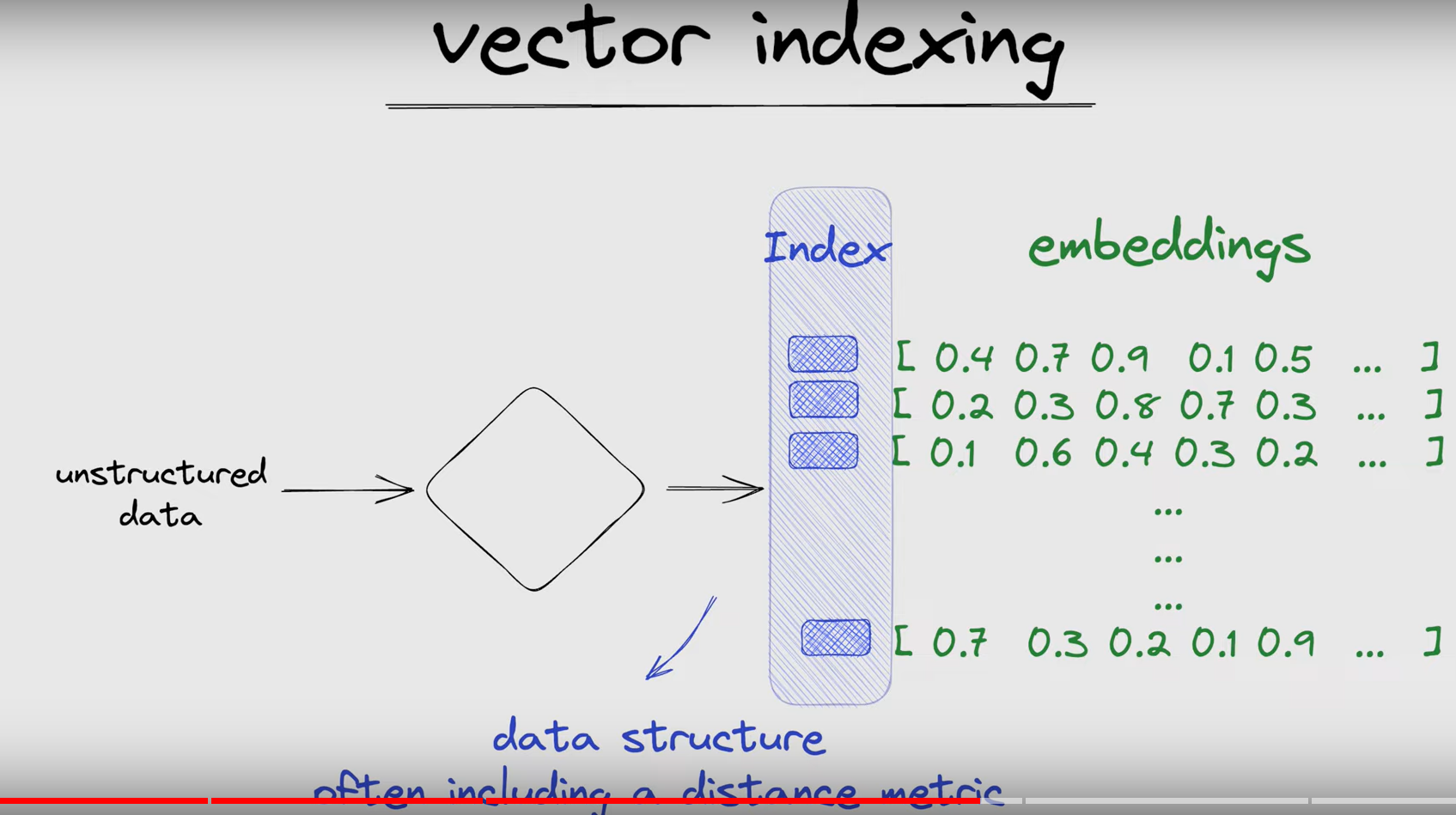
Indexing
Spesso viene aggiunto anche un Index per ogni Embedding che è una struttura dati complessa che spesso include anche dei calcoli prefatti sulla distanza tra gli oggetti in modo che la ricerca possa poi essere veloce.
Casi d’uso per database vettoriali
Puoi utilizzare un database vettoriale per:
- Trovare immagini simili a una determinata immagine in base al contenuto visivo e allo stile
- Trovare documenti simili a un determinato documento in base all’argomento e al sentimento
- Trovare prodotti simili a un determinato prodotto in base alle loro caratteristiche e valutazioni
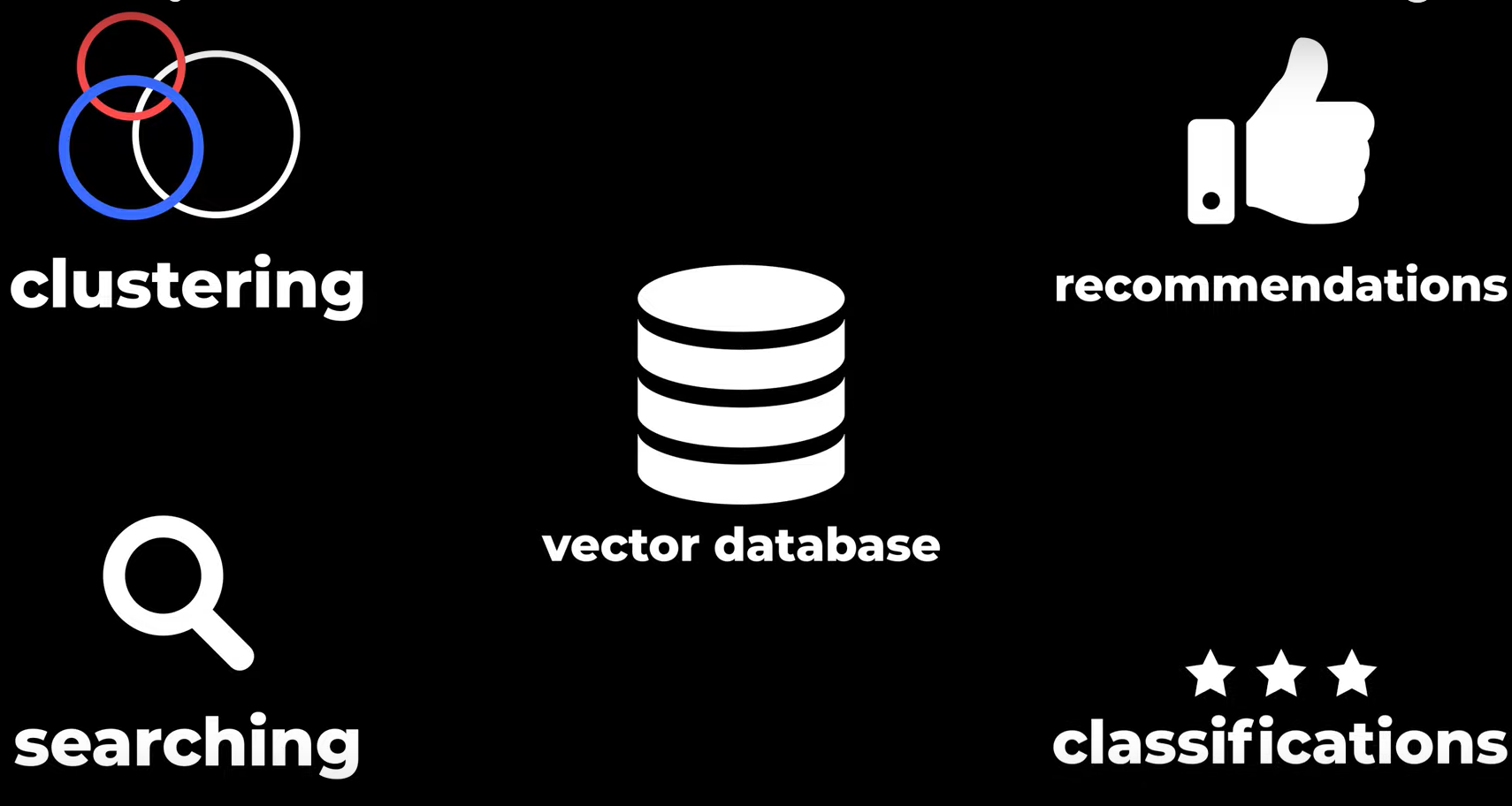
I database vettoriali hanno molti casi d’uso in diversi domini e applicazioni che coinvolgono:
- Clustering: raggruppamento di oggetti per somiglianza (es. immagini correlate in google immagini)
- Searching: reperimento di oggetti che sono rilevanti rispetto ad una query in ingresso
- Recommendations
- Classifications
Esempi
Il database vettoriale più famoso e open source è Qdrant: demo.
Semantic Kernel
In Semantic Kernel posso usare dei connectors per connettermi a database esterni, anche vettoriali. Esempi di connector già pronti: